
Pythonでは、PySparkはsparkのような同様の種類の処理を提供するために使用されるSparkモジュールです。
RDDは、ResilientDistributedDatasetsの略です。 RDDはApacheSparkの基本的なデータ構造と呼ぶことができます。
構文:
|
1 |
spark_app.sparkContext.parallelize((データ)。 |
データを表形式で表示できます。 使用されるデータ構造はDataFrameです。表形式は、データを行と列に格納することを意味します。
構文:
PySparkでは、createDataFrame()メソッドを使用してsparkアプリからDataFrameを作成できます。
構文:
|
1 |
Spark_app.createDataFrame((input_data、columns)。 |
input_dataがこのデータからデータフレームを作成するためのディクショナリまたはリストである可能性があり、input_dataがディクショナリのリストである場合、列は必要ありません。 ネストされたリストの場合は、列名を指定する必要があります。
それでは、PySparkRDDまたはDataFrameで特定のデータを確認する方法について説明しましょう。
PySpark RDDの作成:
この例では、studentsという名前のRDDを作成し、collect()アクションを使用して表示します。
pysparkをインポートする
セッションを作成するための#importSparkSession
pyspark.sqlからインポートSparkSession
#pyspark.rddからRDDをインポートします
pyspark.rddからインポートRDD
#linuxhintという名前のアプリを作成します
spark_app = SparkSession.builder.appName((‘linuxhint’)。.getOrCreate(()。
#5行6属性の学生データを作成する
学生=spark_app.sparkContext.parallelize(([
{‘rollno’:‘001’,‘name’:‘sravan’,‘age’:23,‘height’:5.79,‘weight’:67,‘address’:‘guntur’},
{‘rollno’:‘002’,‘name’:‘ojaswi’,‘age’:16,‘height’:3.79,‘weight’:34,‘address’:‘hyd’},
{‘rollno’:‘003’,‘name’:‘gnanesh chowdary’,‘age’:7,‘height’:2.79,‘weight’:17,‘address’:‘patna’},
{‘rollno’:‘004’,‘name’:‘rohith’,‘age’:9,‘height’:3.69,‘weight’:28,‘address’:‘hyd’},
{‘rollno’:‘005’,‘name’:‘sridevi’,‘age’:37,‘height’:5.59,‘weight’:54,‘address’:‘hyd’}])。
#collect()を使用してRDDを表示する
印刷((student.collect(()。)。
出力:
{‘rollno’: ‘002’, ‘name’: ‘ojaswi’, ‘age’: 16, ‘height’: 3.79, ‘weight’: 34, ‘address’: ‘hyd’},
{‘rollno’: ‘003’, ‘name’: ‘gnanesh chowdary’, ‘age’: 7, ‘height’: 2.79, ‘weight’: 17, ‘address’: ‘patna’},
{‘rollno’: ‘004’, ‘name’: ‘rohith’, ‘age’: 9, ‘height’: 3.69, ‘weight’: 28, ‘address’: ‘hyd’},
{‘rollno’: ‘005’, ‘name’: ‘sridevi’, ‘age’: 37, ‘height’: 5.59, ‘weight’: 54, ‘address’: ‘hyd’}]
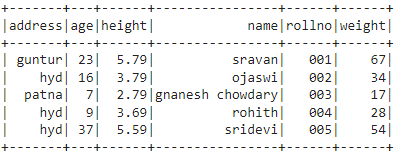
PySpark DataFrameの作成:
この例では、学生のデータからdfという名前のDataFrameを作成し、show()メソッドを使用して表示します。
pysparkをインポートする
セッションを作成するための#importSparkSession
pyspark.sqlからインポートSparkSession
#col関数をインポートする
pyspark.sql.functionsからインポート col
#linuxhintという名前のアプリを作成します
spark_app = SparkSession.builder.appName((‘linuxhint’)。.getOrCreate(()。
#5行6属性の学生データを作成する
学生=[
{‘rollno’:‘001’,‘name’:‘sravan’,‘age’:23,‘height’:5.79,‘weight’:67,‘address’:‘guntur’},
{‘rollno’:‘002’,‘name’:‘ojaswi’,‘age’:16,‘height’:3.79,‘weight’:34,‘address’:‘hyd’},
{‘rollno’:‘003’,‘name’:‘gnanesh chowdary’,‘age’:7,‘height’:2.79,‘weight’:17,‘address’:‘patna’},
{‘rollno’:‘004’,‘name’:‘rohith’,‘age’:9,‘height’:3.69,‘weight’:28,‘address’:‘hyd’},
{‘rollno’:‘005’,‘name’:‘sridevi’,‘age’:37,‘height’:5.59,‘weight’:54,‘address’:‘hyd’}]
#データフレームを作成する
df = spark_app.createDataFrame(( 学生)。
#データフレームを表示する
df.show(()。
出力:
メソッド1:isinstance()
Pythonでは、isinstance()メソッドを使用して、指定されたobject(data)をtype(RDD / DataFrame)と比較します。
構文:
|
1 |
isinstance((オブジェクト、RDD/DataFrame)。 |
2つのパラメータが必要です。
パラメーター:
- オブジェクトはデータを参照します
- RDDはpyspark.rddモジュールで使用可能なタイプであり、DataFrameはpyspark.sqlモジュールで使用可能なタイプです。
ブール値(True / False)を返します。
データがRDDであり、タイプもRDDであるとすると、Trueが返され、そうでない場合はFalseが返されます。
同様に、データがDataFrameで、タイプもDataFrameの場合、Trueを返します。それ以外の場合は、Falseを返します。
例1:
RDDオブジェクトを確認します
この例では、RDDオブジェクトにisinstance()を適用します。
pysparkをインポートする
#importSparkSessionとDataFrameでセッションを作成します
pyspark.sqlからインポートSparkSession、DataFrame
#pyspark.rddからRDDをインポートします
pyspark.rddからインポートRDD
#linuxhintという名前のアプリを作成します
spark_app = SparkSession.builder.appName((‘linuxhint’)。.getOrCreate(()。
#5行6属性の学生データを作成する
学生=spark_app.sparkContext.parallelize(([
{‘rollno’:‘001’,‘name’:‘sravan’,‘age’:23,‘height’:5.79,‘weight’:67,‘address’:‘guntur’},
{‘rollno’:‘002’,‘name’:‘ojaswi’,‘age’:16,‘height’:3.79,‘weight’:34,‘address’:‘hyd’},
{‘rollno’:‘003’,‘name’:‘gnanesh chowdary’,‘age’:7,‘height’:2.79,‘weight’:17,‘address’:‘patna’},
{‘rollno’:‘004’,‘name’:‘rohith’,‘age’:9,‘height’:3.69,‘weight’:28,‘address’:‘hyd’},
{‘rollno’:‘005’,‘name’:‘sridevi’,‘age’:37,‘height’:5.59,‘weight’:54,‘address’:‘hyd’}])。
#学生オブジェクトがRDDであるかどうかを確認します
印刷((isinstance((学生、RDD)。)。
#学生オブジェクトがDataFrameであるかどうかを確認します
印刷((isinstance((学生、DataFrame)。)。
出力:
まず、学生をRDDと比較しました。 RDDであるため、Trueを返しました。 次に、学生をDataFrameと比較しましたが、RDD(DataFrameではない)であるため、Falseが返されました。
例2:
DataFrameオブジェクトを確認します
この例では、DataFrameオブジェクトにisinstance()を適用します。
pysparkをインポートする
セッションを作成するための#importSparkSession、DataFrame
pyspark.sqlからインポートSparkSession、DataFrame
#col関数をインポートする
pyspark.sql.functionsからインポート col
#pyspark.rddからRDDをインポートします
pyspark.rddからインポートRDD
#linuxhintという名前のアプリを作成します
spark_app = SparkSession.builder.appName((‘linuxhint’)。.getOrCreate(()。
#5行6属性の学生データを作成する
学生=[
{‘rollno’:‘001’,‘name’:‘sravan’,‘age’:23,‘height’:5.79,‘weight’:67,‘address’:‘guntur’},
{‘rollno’:‘002’,‘name’:‘ojaswi’,‘age’:16,‘height’:3.79,‘weight’:34,‘address’:‘hyd’},
{‘rollno’:‘003’,‘name’:‘gnanesh chowdary’,‘age’:7,‘height’:2.79,‘weight’:17,‘address’:‘patna’},
{‘rollno’:‘004’,‘name’:‘rohith’,‘age’:9,‘height’:3.69,‘weight’:28,‘address’:‘hyd’},
{‘rollno’:‘005’,‘name’:‘sridevi’,‘age’:37,‘height’:5.59,‘weight’:54,‘address’:‘hyd’}]
#データフレームを作成する
df = spark_app.createDataFrame(( 学生)。
#dfがRDDかどうかを確認します
印刷((isinstance((df、RDD)。)。
#dfがDataFrameかどうかを確認します
印刷((isinstance((df、DataFrame)。)。
出力:
まず、dfとRDDを比較しました。 DataFrameであるためFalseを返し、dfとDataFrameを比較しました。 DataFrame(RDDではない)であるため、Trueを返しました。
方法2:type()
Pythonでは、type()メソッドは指定されたオブジェクトのクラスを返します。 パラメータとしてオブジェクトを取ります。
構文:
例1:
RDDオブジェクトを確認します。
type()をRDDオブジェクトに適用します。
pysparkをインポートする
セッションを作成するための#importSparkSession
pyspark.sqlからインポートSparkSession
#pyspark.rddからRDDをインポートします
pyspark.rddからインポートRDD
#linuxhintという名前のアプリを作成します
spark_app = SparkSession.builder.appName((‘linuxhint’)。.getOrCreate(()。
#5行6属性の学生データを作成する
学生=spark_app.sparkContext.parallelize(([
{‘rollno’:‘001’,‘name’:‘sravan’,‘age’:23,‘height’:5.79,‘weight’:67,‘address’:‘guntur’},
{‘rollno’:‘002’,‘name’:‘ojaswi’,‘age’:16,‘height’:3.79,‘weight’:34,‘address’:‘hyd’},
{‘rollno’:‘003’,‘name’:‘gnanesh chowdary’,‘age’:7,‘height’:2.79,‘weight’:17,‘address’:‘patna’},
{‘rollno’:‘004’,‘name’:‘rohith’,‘age’:9,‘height’:3.69,‘weight’:28,‘address’:‘hyd’},
{‘rollno’:‘005’,‘name’:‘sridevi’,‘age’:37,‘height’:5.59,‘weight’:54,‘address’:‘hyd’}])。
#生徒のタイプを確認する
印刷((タイプ((学生)。)。
出力:
|
1 |
<<クラス ‘pyspark.rdd.RDD’>> |
クラスRDDが返されることがわかります。
例2:
DataFrameオブジェクトを確認します。
DataFrameオブジェクトにtype()を適用します。
pysparkをインポートする
セッションを作成するための#importSparkSession
pyspark.sqlからインポートSparkSession
#col関数をインポートする
pyspark.sql.functionsからインポート col
#linuxhintという名前のアプリを作成します
spark_app = SparkSession.builder.appName((‘linuxhint’)。.getOrCreate(()。
#5行6属性の学生データを作成する
学生=[
{‘rollno’:‘001’,‘name’:‘sravan’,‘age’:23,‘height’:5.79,‘weight’:67,‘address’:‘guntur’},
{‘rollno’:‘002’,‘name’:‘ojaswi’,‘age’:16,‘height’:3.79,‘weight’:34,‘address’:‘hyd’},
{‘rollno’:‘003’,‘name’:‘gnanesh chowdary’,‘age’:7,‘height’:2.79,‘weight’:17,‘address’:‘patna’},
{‘rollno’:‘004’,‘name’:‘rohith’,‘age’:9,‘height’:3.69,‘weight’:28,‘address’:‘hyd’},
{‘rollno’:‘005’,‘name’:‘sridevi’,‘age’:37,‘height’:5.59,‘weight’:54,‘address’:‘hyd’}]
#データフレームを作成する
df = spark_app.createDataFrame(( 学生)。
#dfの種類を確認する
印刷((タイプ((df)。)。
出力:
|
1 |
<<クラス ‘pyspark.sql.dataframe.DataFrame’>> |
クラスDataFrameが返されることがわかります。
結論
上記の記事では、isinstance()とtype()を使用して、指定されたデータまたはオブジェクトがRDDまたはDataFrameであるかどうかを確認する2つの方法を見ました。 isinstance()は、指定されたオブジェクトに基づいてブール値になることに注意する必要があります。オブジェクトタイプが同じ場合は、Trueを返し、それ以外の場合はFalseを返します。 また、type()は、指定されたデータまたはオブジェクトのクラスを返すために使用されます。
The post 指定されたデータがPySparkRDDまたはDataFrameであることを確認してください appeared first on Gamingsym Japan.