
今回は、Pythonを使ってAmazonの口コミをスクレイプする方法について紹介したいと思います。
以前こちらのページで、WindowsFormとC#を使ってAmazonの口コミをスクレイプする方法を紹介しました。
そして、こちらのページでは、Pythonを使ったスクレイプ用の自作クラスを紹介しました。
今回はこの2つの記事を合体させたような内容となります。
このページだけ読んで頂いても事が足りる用にしてありますが、スクレイプについて詳しく知りたい方は、併せてこちらの記事もご一読ください。
概要
今回は関数として作成しており、引数にamazon の商品URLを渡すと、口コミ収集してくれるようになっています。
関数内部では、こちらの記事で紹介した自作クラス(Scrape)を呼び出しています。

私が今回解析したURLやHTMLのパターン以外のものや、amazon のページの仕様が変わった場合は、うまくスクレイプできなくなりますがご了承ください。
関数のソースは次の様になります。
出来るだけ多くのコメントを記載していますので、ソースに目を通していただければ、おおよそのことが分かるかと思います。
def scrape_amazon(url):
scr = Scrape(wait=2,max=5)
#urlの /dp/ 直後に商品IDがあるので、それを取得
pos = url.find('/dp/') + 4
#商品IDは10桁なので、10桁分切り取る
id = url[pos:pos + 10]
#最大500ページ分(500×10=5000レビュー分)を読み出すループ
for n in range(1,500):
#商品IDからレビュー記事のページを生成
target = f'https://www.amazon.co.jp/product-reviews/{id}/ref=cm_cr_arp_d_viewopt_sr?ie=UTF8&filterByStar=all_stars&reviewerType=all_reviews&pageNumber={n}#reviews-filter-bar'
print(f'get:{target}')
#ページを読み込む
soup = scr.request(target)
#ページ内のレビューを全て取得(1ページ10レビュー)
reviews = soup.find_all('div',class_='a-section review aok-relative')
print(f'レビュー数:{len(reviews)}')
#レビューの数だけループ
for review in reviews:
#日本のレビューアが書いたレビューのタイトルを取得
title = scr.get_text(review.find('a',class_='a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold'))
#外国人のレビューアが書いたレビューのタイトルを取得(日本人と外国人ではタグが異なっていた)
title = scr.get_text(review.find('span',class_='cr-original-review-content')) if title.strip() == '' else title
#レビューアの名前を取得
name = scr.get_text(review.find('span',class_='a-profile-name'))
#評価は「5つ星のうち4.3」という記述のされ方なので、「ち」以降の数値のみを取得
star = scr.get_text(review.find('span',class_='a-icon-alt'))
star = star[star.find('ち')+1:]
#日付けは「2022年6月16日に日本でレビュー済み」という記述のされ方なので、「に」までの文字列を取得
date = scr.get_text(review.find('span',class_='a-size-base a-color-secondary review-date'))
date = date[:date.find('に')]
#レビューの内容を取得
comment = scr.get_text(review.find('span',class_='a-size-base review-text review-text-content'))
#CSV出力用のDFに登録
scr.add_df([title,name,star,date,comment],['title','name','star','date','comment'],['\n'])
#ページ内のレビュー数が10未満なら最後と判断してループを抜ける
if len(reviews) < 10:
break
#CSVファイルに口コミを出力
scr.to_csv("p:/amazon口コミ.csv")
関数の使い方
使い方は簡単で、引数にスクレイプしたい商品のURLを渡すだけです。
scrape_amazon(スクレイプしたいURL)
scrape_amazon('https://www.amazon.co.jp/%E3%82%B7%E3%83%AA%E3%82%B3%E3%83%B3%E3%83%91%E3%83%AF%E3%83%BC-USB%E3%83%A1%E3%83%A2%E3%83%AA-USB3-0-%E3%83%8D%E3%82%A4%E3%83%93%E3%83%BC%E3%83%96%E3%83%AB%E3%83%BC-SP064GBUF3B05V1D/dp/B00GOJ4R0U/ref=cm_cr_arp_d_product_top?ie=UTF8')
アマゾンのページのスクリーンショットをサンプルで掲載したいところですが、違反になるので割愛します。
下記商品のスクレイピングなので、実際にページに移動してご確認下さい。

下記は、スクレイピングした結果のCSVをEXCELで開いた画面です。
name は個人情報に抵触するかどうかわかりませんが、念のためボカしています。
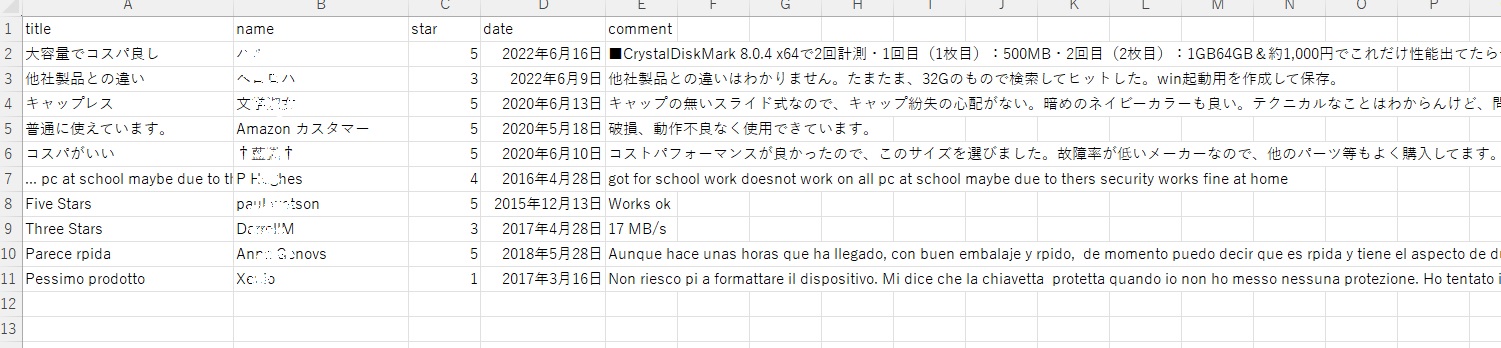
全ソース(自作クラスを含む)
自作クラスを含む全てのソースを掲載しておきます。
# pip install requests
# pip install beautifulsoup4
import requests
from bs4 import BeautifulSoup
import time
import random
import pandas as pd
import time
import datetime
#------------------- 自作のScrapクラス ----------------
class Scrape():
def __init__(self,wait=1,max=None):
self.response = None
self.df = pd.DataFrame()
self.wait = wait
self.max = max
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36"}
self.timeout = 5
def request(self,url,wait=None,max=None,console=True):
'''
指定したURLからページを取得する。
取得後にwaitで指定された秒数だけ待機する。
max が指定された場合、waitが最小値、maxが最大値の間でランダムに待機する。
Params
---------------------
url:str
URL
wait:int
ウェイト秒
max:int
ウェイト秒の最大値
console:bool
状況をコンソール出力するか
Returns
---------------------
soup:BeautifulSoupの戻り値
'''
self.wait = self.wait if wait is None else wait
self.max = self.max if max is None else max
start = time.time()
response = requests.get(url,headers=self.headers,timeout = self.timeout)
time.sleep(random.randint(self.wait,self.wait if self.max is None else self.max))
if console:
tm = datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S')
lap = time.time() - start
print(f'{tm} : {url} 経過時間 : {lap:.3f} 秒')
return BeautifulSoup(response.content, "html.parser")
def get_href(self,soup,contains = None):
'''
soupの中からアンカータグを検索し、空でないurlをリストで返す
containsが指定された場合、更にその文字列が含まれるurlだけを返す
Params
---------------------
soup:str
BeautifulSoupの戻り値
contains:str
抽出条件となる文字列
Returns
---------------------
return :[str]
条件を満たすurlのリスト
'''
urls = list(set([url.get('href') for url in soup.find_all('a')]))
if contains is not None:
return [url for url in urls if self.contains(url,contains)]
return [url for url in urls if urls is not None or urls.strip() != '']
def get_src(self,soup,contains = None):
'''
soupの中からimgタグを検索し、空でないsrcをリストで返す
containsが指定された場合、更にその文字列が含まれるurlだけを返す
Params
---------------------
soup:str
BeautifulSoupの戻り値
contains:str
抽出条件となる文字列
Returns
---------------------
return :[str]
条件を満たすurlのリスト
'''
urls = list(set([url.get('src') for url in soup.find_all('img')]))
if contains is not None:
return [url for url in urls if contains(url,self.contains)]
return [url for url in urls if urls is not None or urls.strip() != '']
def contains(self,line,kwd):
'''
line に kwd が含まれているかチェックする。
line が None か '' の場合、或いは kwd が None 又は '' の場合は Trueを返す。
Params
---------------------
line:str
HTMLの文字列
contains:str
抽出条件となる文字列
Returns
---------------------
return :[str]
条件を満たすurlのリスト
'''
if line is None or line.strip() == '':
return False
if kwd is None or kwd == '':
return True
return kwd in line
def omit_char(self,values,omits):
'''
リストで指定した文字、又は文字列を削除する
Params
---------------------
values:str
対象文字列
omits:str
削除したい文字、又は文字列
Returns
---------------------
return :str
不要な文字を削除した文字列
'''
for n in range(len(values)):
for omit in omits:
values[n] = values[n].replace(omit,'')
return values
def add_df(self,values,columns,omits = None):
'''
指定した値を DataFrame に行として追加する
omits に削除したい文字列をリストで指定可能
Params
---------------------
values:[str]
列名
omits:[str]
削除したい文字、又は文字列
'''
if omits is not None:
values = self.omit_char(values,omits)
columns = self.omit_char(columns,omits)
df = pd.DataFrame(values,index=self.rename_column(columns))
self.df = pd.concat([self.df,df.T])
def to_csv(self,filename,dropcolumns=None):
'''
DataFrame をCSVとして出力する
dropcolumns に削除したい列をリストで指定可能
Params
---------------------
filename:str
ファイル名
dropcolumns:[str]
削除したい列名
'''
if dropcolumns is not None:
self.df.drop(dropcolumns,axis=1,inplace=True)
self.df.to_csv(filename,index=False,encoding="shift-jis",errors="ignore")
def get_text(self,soup):
'''
渡された soup が Noneでなければ textプロパティの値を返す
Params
---------------------
soup: bs4.element.Tag
bs4でfindした結果の戻り値
Returns
---------------------
return :str
textプロパティに格納されている文字列
'''
return ' ' if soup == None else soup.text
def rename_column(self,columns):
'''
重複するカラム名の末尾に連番を付与し、ユニークなカラム名にする
例 ['A','B','B',B'] → ['A','B','B_1','B_2']
Params
---------------------
columns: [str]
カラム名のリスト
Returns
---------------------
return :str
重複するカラム名の末尾に連番が付与されたリスト
'''
lst = list(set(columns))
for column in columns:
dupl = columns.count(column)
if dupl > 1:
cnt = 0
for n in range(0,len(columns)):
if columns[n] == column:
if cnt > 0:
columns[n] = f'{column}_{cnt}'
cnt += 1
return columns
def write_log(self,filename,message):
'''
指定されたファイル名にmessageを追記する。
Params
---------------------
filename: str
ファイル名
message: str
ファイルに追記する文字列
'''
message += '\n'
with open(filename, 'a', encoding='shift-jis') as f:
f.write(message)
print(message)
def read_log(self,filename):
'''
指定されたファイル名を読み込んでリストで返す
Params
---------------------
filename: str
ファイル名
Returns
---------------------
return :[str]
読み込んだ結果
'''
with open(filename, 'r', encoding='shift-jis') as f:
lines = f.read()
return lines
#------------------- アマゾン口コミのスクレイピング用関数 ----------------
def scrape_amazon(url):
scr = Scrape(wait=2,max=5)
pos = url.find('/dp/') + 4
id = url[pos:pos + 10]
for n in range(1,100):
target = f'https://www.amazon.co.jp/product-reviews/{id}/ref=cm_cr_arp_d_viewopt_sr?ie=UTF8&filterByStar=all_stars&reviewerType=all_reviews&pageNumber={n}#reviews-filter-bar'
print(f'get:{target}')
soup = scr.request(target)
reviews = soup.find_all('div',class_='a-section review aok-relative')
print(f'レビュー数:{len(reviews)}')
for review in reviews:
title = scr.get_text(review.find('a',class_='a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold'))
title = scr.get_text(review.find('span',class_='cr-original-review-content')) if title.strip() == '' else title
name = scr.get_text(review.find('span',class_='a-profile-name'))
star = scr.get_text(review.find('span',class_='a-icon-alt'))
star = star[star.find('ち')+1:]
date = scr.get_text(review.find('span',class_='a-size-base a-color-secondary review-date'))
date = date[:date.find('に')]
comment = scr.get_text(review.find('span',class_='a-size-base review-text review-text-content'))
scr.add_df([title,name,star,date,comment],['title','name','star','date','comment'],['\n'])
if len(reviews) < 10:
break
scr.to_csv("p:/amazon口コミ.csv")
まとめ
今回は、Amazonの口コミをPythonでスクレイピングする方法について紹介しました。
関数化しているので、コピペしてお使いいただけます。
但し、全ての商品について確認できておりませんので、商品の中にはうまくスクレイピングできない可能性もあります。
また、将来Amazonのページの仕様が変わった場合もスクレイピングできなくなりますので、その場合はソースのコメントを見ながら、適宜修正して頂ければと思います。
今回のスクレイピングで得た口コミに対して、ワードクラウドや文書要約など適応すれば、全ての口コミに目を通すことなく、全体の概要が掴めるかもしれませんので、興味のある方はお試しください。
今回の記事が皆様のプログラミングの一助になれば幸いです。