
Metaは、ユニバーサル言語トランスレータの作成に向けて新たな一歩を踏み出しました。
同社は、200を超える言語を翻訳するAIモデルをオープンソース化しており、その多くは既存のシステムではサポートされていません。
この調査は、今年初めに開始されたメタイニシアチブの一部です。
ご挨拶、ヒューマノイド
今すぐニュースレターを購読して、受信トレイにあるお気に入りのAIストーリーを毎週まとめてください。
「私たちはこのプロジェクトを呼んでいます 言語が残されていない、およびNLLBで使用したAIモデリング手法は、FacebookとInstagramで、世界中の何十億もの人々が話す言語の高品質な翻訳を作成するのに役立っています」とMetaCEOのMarkZuckerbergはFacebookの投稿で述べています。
NLLBは、マオリ語やマルタ語などの低リソース言語に焦点を当てています。 世界中のほとんどの人がこれらの言語を話しますが、AI翻訳に通常必要なトレーニングデータが不足しています。
Metaの新しいモデルは、この課題を克服するために設計されました。
これを行うために、研究者は最初に彼らのニーズを理解するために十分にサービスされていない言語の話者にインタビューしました。 次に、彼らは次のトレーニング文を生成する新しいデータマイニング技術を開発しました 低リソース言語。
次に、マイニングされたデータと人間が翻訳したデータを組み合わせてモデルをトレーニングしました。
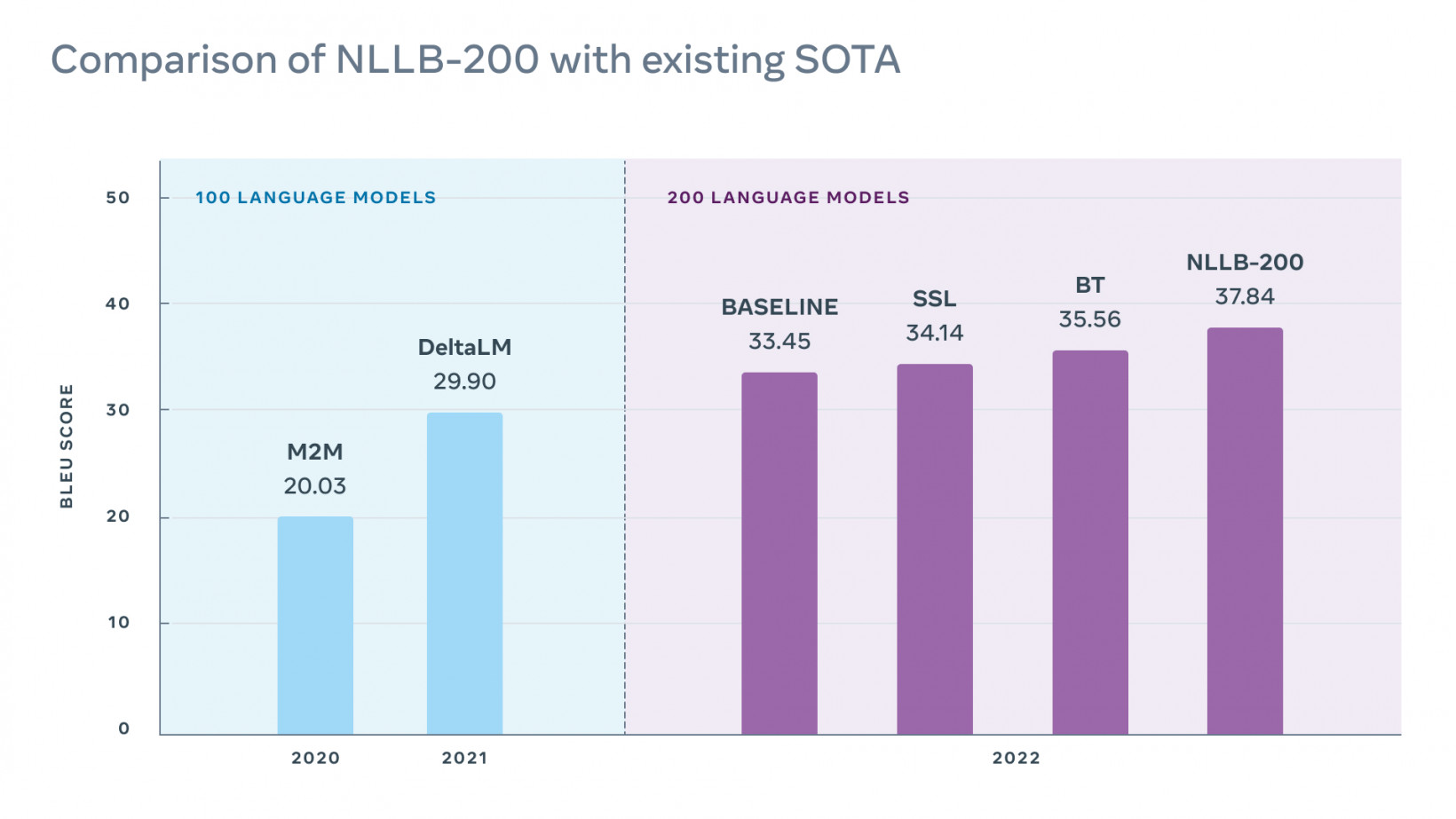
その結果がNLLB-200です。これは202言語向けの大規模な多言語翻訳システムです。
チームは、低リソース言語の翻訳を評価するFLORES-101データセットでモデルのパフォーマンスを評価しました。
「言語の数が2倍になったにもかかわらず、最終的なモデルは、Flores-101の以前の最先端モデルよりも40%優れたパフォーマンスを発揮します。」 研究の著者は書いた。
この手法により、Facebook、Instagram、およびWikipediaでの機械翻訳がすでに改善されています。 メタも持っています すべてのベンチマーク、データスクリプト、およびモデルをオープンソース化しました さらなる研究をサポートするため。
もちろん、これはMetaにもメリットがあります。
すべての人にオープンソース
ザッカーバーグの絶え間ない成長への意欲は、最近障害にぶつかった。 2月、Facebookは18年の歴史の中で初めて毎日のユーザーを失いました。
Metaが翻訳の品質を向上させることができれば、そのアプリをより幅広いユーザーベースにとって魅力的なものにすることができます。
必然的に、同社は研究がメタバースで大きな役割を果たすことを期待しています。 包含に関する懸念が高まっています。 ただし、ビジネスの既存のアプリにもメリットがあります。
翻訳の問題は長い間Metaに問題を引き起こしてきました。 2017年、イスラエルの警察 パレスチナ人を逮捕 Facebookが「おはよう」という投稿を「攻撃する」と翻訳した後。
同社はまた、誤った情報や悪意のある表現を監視するのに苦労しています リソースの少ない言語で。
新しい調査により、これらのリスクが軽減され、ユーザーエクスペリエンスが向上する可能性があります。 Metaの名誉のために、同社はライバルにもこの仕事から利益を得る機会を与えました。 モデルのオープンソーシングは、十分なサービスを受けていない、または脅威にさらされている言語の話者もサポートすることを願っています。
この場合、メタに利益をもたらすものは人類にも利益をもたらす可能性があります。 また、万能翻訳機のファンタジーを現実に近づけます。
The post Metaの新しいAIは、私たちを世界共通の言語翻訳者に一歩近づけます appeared first on Gamingsym Japan.