
Seabornは、統計的ビジュアルをプロットできるPython用の優れた視覚化モジュールです。 これはMatplotlibソフトウェアに基づいており、Pandasのデータ構造と緊密に接続されています。 教師なし学習では、クラスタリング手法が構造化データの取得に役立ちます。 この記事では、クラスターマップとは何か、およびクラスターマップを作成してさまざまな目的で使用する方法について説明します。
Seabornのクラスターマップの構文
Seabornクラスターマップの簡単な構文は次のとおりです。
|
1 |
海生まれ。クラスターマップ((データ、、 standard_scale=なし、 figsize=((6、 8)。、 ** kwargs)。 |
以下では、Seabornクラスター関数内で渡されるパラメーターといくつかのオプションのパラメーターについて説明しました。
データ:クラスタリングには、長方形のデータが使用されます。 NAは許可されていません。
ピボット_kws:データが整然としたデータフレームにある場合は、キーワードパラメータを使用して、ピボットのある長方形のデータフレームを作成できます。
方法:クラスターを計算するには、リンケージアプローチを適用します。 詳細については、scipy.cluster.hierarchy.linkage()のドキュメントを参照してください。
メトリック:データは距離で測定する必要があります。 その他のパラメーターは、scipy.spatial.distance.pdist()のドキュメントに記載されています。 すべてのリンケージマトリックスを手動で作成し、行として指定できます。 列リンケージは、行と列のメトリック(または方法論)を使用します。
z_score:列または行のzスコアを計算する必要があるかどうか。 Zスコアはz=(x –平均)/ stdとして計算されます。これは、各行(列)の値が行(列)の平均から差し引かれ、行(列)の標準偏差(列)で除算されることを意味します。 これにより、各行(列)の平均が0で変動が1になることが保証されます。
standard_scale:そのディメンションを正規化するかどうかは、最小値を減算し、各行または列を最大値で除算することを意味します。
figsize:幅と高さを含むフィギュア全体のサイズ。
{行、列} _cluster:Trueの場合、行と列は一緒にクラスター化されます。
{行、列} _colors:行または列にラベルを付けるための色。 コレクション内のデータが集合的にクラスター化されているかどうかを確認するために使用できます。 ラベルのいくつかの色レベルでは、パンダの形式で提供される場合は、スタックリストまたはDataFrameを使用できます。 DataFrameまたはPandasはどちらも適切なオプションです。 カラーラベルは、DataFramesフィールド名またはシリーズ名から派生します。 DataFrame / Seriesの色もインデックスによってデータセットに関連付けられ、色が適切な順序で表示されるようにします。
{樹状図、色} _ratio:グラフィックサイズのパーセンテージは、2つの境界セクション専用です。 ペアが指定されている場合、それは行と列の比率を参照します。
cbar_pos:図では、カラーバーの軸は正しい位置にあります。[なし]に設定すると、カラーバーはオフになります。
kwargs:ヒートマップは他のすべてのキーワードparameters()を受け取ります。
SeabornのClustermap関数を介して階層的クラスターを使用してヒートマップを作成します。 SeabornのClustermapは本当に便利な関数です。 いくつかの例を使用して、それを利用する方法を示します。
Seabornのクラスターマップは、行と列のクラスター化を同時に表示しながら、マトリックス要素をヒートマップとして視覚化できるマトリックスグラフィックです。 次の例では、必要なライブラリを取り込みました。 次に、従業員の名前、ID、年齢、給与を含むデータフレームを作成しました。 次に、pd.dataframe関数を使用して、このデータフレームをパンダに変換しました。 set関数を使用して、NameフィールドでEmployee_dataのインデックスを設定します。
この後、Seabornクラスター関数を呼び出し、Employee_dataをその関数に渡すことにより、このデータフレームのクラスターマップを作成しました。 別のキーワード引数annotが使用され、Trueに設定されます。 このパラメーターを使用すると、クラスターマップのヒートマップに表示される実数を確認できます。
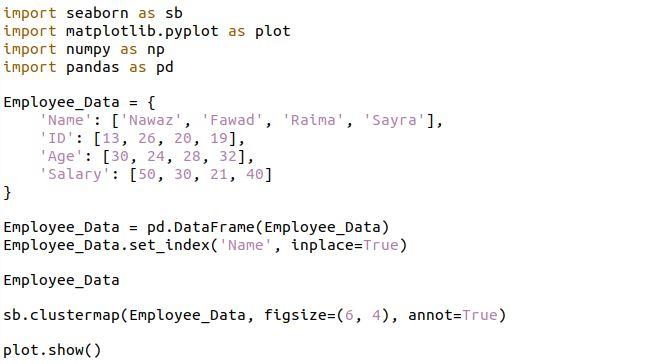
クラスタマップの出力は次の図にあります。 行と列はSeabornによって再配置されていることに注意してください。
サンプルデータセット「mpg」を使用してクラスターマップを作成しましょう。 これらのクラスターマップに送信するデータを、データフレームの列数のみにフィルターする必要があります。
必要なライブラリのインポートから始めます。 「DataFrame_mpg」変数内に「mpg」のデータセットをロードしました。 また、dropna関数を使用して、データフレーム内のnull行を削除しました。 「mpg」データフレーム内に列の名前と列のサイズを印刷しました。 次に、「mpg」データフレーム全体が指定された列で渡されるクラスターマップ関数があります。
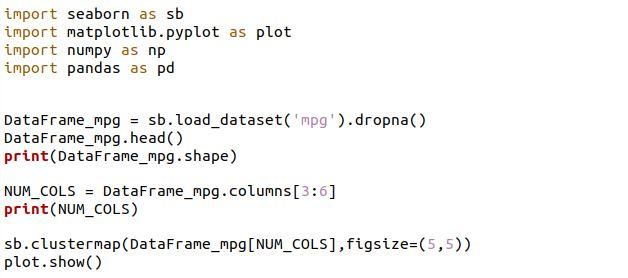
3つの列がコンソールに表示されます。

前のコードを実行すると、明るい色の列が1つしかないクラスターマップが表示されます。 これは、これらのいくつかの列のスケールが異なるためです。
例3:
クラスタマップ関数内のデータをスケーリングするためのいくつかのオプションがあります。 しかし、簡単な方法の1つは、標準のスケール引数を利用することです。 各行をスケーリングする場合は、引数としてゼロの値を渡す必要があります。 各列をスケーリングする場合、値は1になります。これでスケール値は1になります。また、値を単一として割り当てたクラスター関数内にメソッド引数を渡しました。 文字列は、最小限のリンクである単一の値として渡すことができます。
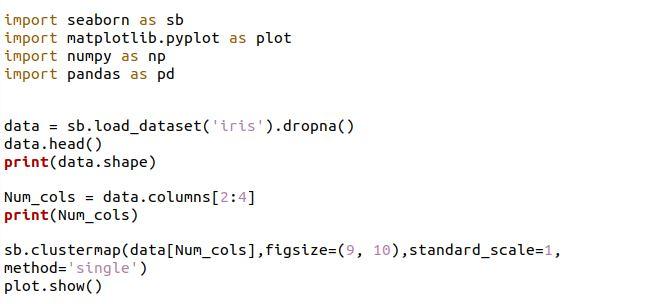
データフレームの「iris」クラスターマップは、スケールとメソッドのパラメーターを渡したため、図では少し異なります。
例4:
ここでは、Seabornクラスターマップ関数内にrow_colorパラメーターを追加しました。 各色をフィールドの種に割り当て、データフレームペンギンの種の列から情報を引き出しました。
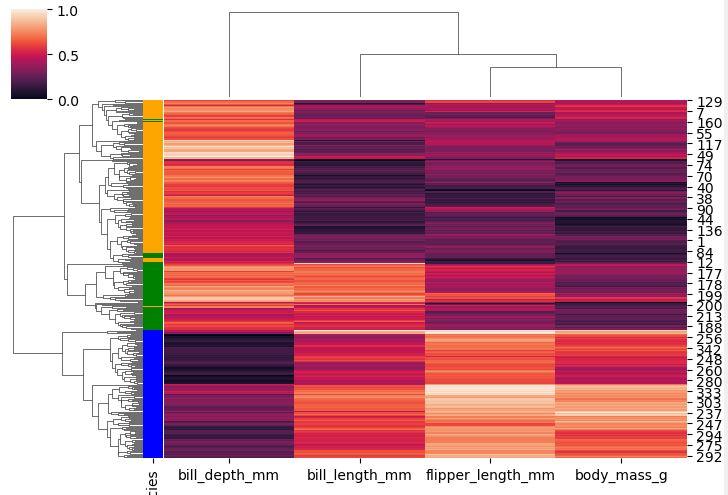
結論
これで、渡されたさまざまなパラメーターの例をいくつか使用して説明したので、Seabornクラスターマップを確立できます。 SeabornのClustermapには、データから長さまたは類似グリッドを計算してヒートマップを作成するための多くの選択肢もあります。
The post Seaborn Cluster Map appeared first on Gamingsym Japan.