
フレーズやキーワードを使用している資料を見る場合、最良の例はGoogle検索です。 MongoDB全文検索では、文字列または文字列の配列を使用して、ドキュメント内の任意の列にテキストインデックスを確立できます。
Ubuntu 20.04のMongoDBでの全文検索の構文?
上記の構文は次のとおりです。
db.Collection_Name.find(({{$ text: {{$ search: “ストリング”}})。
find()関数は、上記の構文で次のパラメーターとともに使用されます。
- Collection_Name:既存のコレクションの名前を参照します。
- 探す:検索を使用して検索するために実行されます。
- $ text:私たちの目的を満たすコレクション検索を行うために使用されます。
- $ search:検索の実行に使用されます。
- 弦:コレクションで検索する特定の文字列を参照し、検索機能を使用して正確な単語を検索できます。
Ubuntu20.04のMongoDBで$text演算子を操作する:
テキストリストは、文字列コンテンツのテキスト検索を支援するためにMongoDBによって提供されます。 文字列値または文字列コンポーネントの範囲を持つ任意のフィールドをテキストレコードに含めることができます。 テキスト検索の質問を行うには、コレクションにテキストレコードが必要です。 コレクションでさえ、トピック検索レコードは1つしかありません。 リストは複数のフィールドにまたがることができます。
Ubuntu20.04のMongoDBで全文検索がどのように実行されるか
ここで、物事をよりよく理解するために特定の例を見てください。 まず、「myDemo」という名前のデータベースを作成しました。 このデータベース内で、コレクションを「フルーツ」として定義しました。 次に、insertManyクエリを使用してコレクションドキュメントを挿入します。スクリーンショットには、以下のコレクション「フルーツ」ドキュメントのフィールドとこれらのフィールドに対する値が表示されています。
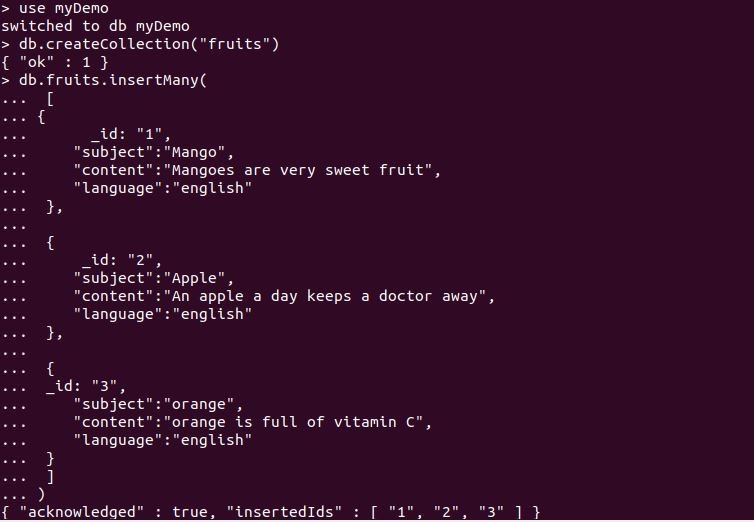
クエリ「db.fruits.find()」は、次のようにコレクション「fruits」の属性とエンティティになります。 「果物」の収集のために3つの文書が記録されています。

それでは、全文検索を実行する方法を調べてみましょう。
例1:Ubuntu 20.04のMongoDBでテキストインデックスを作成する:
MongoDBの全文検索機能を使用する前に、データセットにテキストインデックスを確立する必要があります。 インデックスは、コレクション内の各テキストからの限られたデータをドキュメント自体から分離する一意のデータ構造です。 全文検索を実行する方法を見てみましょう。
テキストインデックスは、従来のインデックスと同じ方法で作成され、昇順/降順を定義する代わりに、textキーワードを定義します。
![]()
上記に、全文検索のクエリがあります。 createIndex()メソッドを使用してテキストインデックスを作成しました。 「subject」と「content」の2つのフィールドをインデックスタイプのテキストに設定します。
MongoDBシェルでcreateIndexクエリを実行すると、次の出力でインデックスの作成が確認されます。

例2:Ubuntu20.04のMongoDBでフルテキストから単語またはフレーズを検索します。
1つまたは複数の単一の単語で構成されるドキュメントを検索することは、おそらく最も広範囲にわたる検索の課題です。 ユーザーはおそらく、特定の検索フレーズを表示する場所の選択にWebブラウザーが適応できることを期待しています。 テキストインデックスを使用する場合、MongoDBは同じ方法で一般的な検索クエリにアプローチします。 いくつかの例を使用して、このステップでは、MongoDBが検索リクエストを処理する方法について説明します。
![]()
ここに、クエリ「db.fruits.find()」があります。 クエリは$text演算子を使用します。これは、クエリが以前に定義したテキストインデックスを利用することをここでMongoDBに通知します。 また、各コレクションで許可されるテキストインデックスは1つだけです。 次に、$ text演算子内に、指定されたドキュメントから「sweet」の値を検索するために使用される$searchという別の演算子があります。
ご覧のとおり、テキストコンテンツが「甘い」のドキュメントは1つだけです。 上記のクエリを実行すると、テキストコンテンツが「甘い」のドキュメントの詳細全体が次のように表示されます。

現在、次のクエリを使用して2つの単語を検索しています。
![]()
$text演算子内で呼び出される$search演算子に2語の「ビタミンC」を与えました。 クエリを実行すると、次のようにテキストにビタミンCがリストされているドキュメントレコードが表示されます。

例3:Ubuntu 20.04のMongoDBでの全文検索結果のスコアリングと並べ替え:
各ドキュメントは、テキスト検索から、検索クエリとの関連性を示すスコアを受け取ります。 このスコアは、検索結果のすべてのレコードを分類するために使用されます。 スコアが高いほど、コンテストの意味が高くなります。

$search演算子を使用して「Mangoes」と「Orange」の2つの単語を検索する$text演算子があります。 次に、取得したドキュメントから指定されたメタデータを返す$meta演算子を使用するプロジェクション{score:$ meta:“ textScore”}があります。 この場合、MongoDBの全文検索エンジンの組み込みコンポーネントであり、検索関連性スコアを保持するtextScoreメタデータが返されます。
フィルタドキュメントに記載されているように、結果のドキュメントには、クエリの実行後にscoreという名前の新しいフィールドが追加されます。

これで、プロジェクション{score:$ meta:“ textScore”}にソート関数を使用しました。 ソートドキュメントは、プロジェクションドキュメントと同じ構文を使用します。

テキストマンゴーは関連性スコアが最も高いため、出力画面の最初に表示されます。

結論:
このチュートリアルに従って、MongoDBの全文検索機能の使用方法を習得しました。 テキストインデックスを作成し、1つおよび複数の単語、フレーズ全体、および除外を含むテキスト検索クエリを作成しました。 また、返却された論文の関連性を評価し、最も関連性の高いアイテムを最初に表示するように検索結果を並べ替えました。
The post MongoDB全文検索 appeared first on Gamingsym Japan.