
SQLiteは、ユーザーに新しい句のセットを提供します。そのうちの1つはGROUPBYです。 本質的に、GROUP BYステートメントは、他のselectコマンドと連携して機能し、コンテンツを異なる方法で編成するselectクエリの追加コンポーネントです。 GROUP BYステートメントは、ユーザーのクエリに基づいて一連の行を作成するために使用されています。 また、すべてのグループに1つまたは複数の行を提供します。 特定のテーブルに関する詳細情報を提供するために、GROUPBYコマンドのパラメーターとしてSUMやCOUNTなどの発生主義会計方法を採用する場合があります。 SELECTクエリのFROMコンポーネントの後には、GROUPBYステートメントが続きます。 クエリにWHEREコマンドが含まれている場合は、その後にGROUPBYコマンドを配置する必要があります。
SELECTクエリがGROUPBYコマンドを使用した累積ステートメントである場合、GROUP BYコマンドの要素として定義された提供された各変数は、データのすべての列に対して評価されます。 次に、各エントリは、結果に基づいて「コレクション」に割り当てられます。 同じGROUPBYコマンドの結果を持つエントリは、関連するグループに割り当てられます。 空の値は、行を集約するために同一であると見なされます。 GROUP BYコマンドで特定の引数を評価する場合、テキスト値を分析するためのグループ化構成を選択するための通常の基準が適用されます。 GROUP BYコマンドで提供される引数は、出力に表示されるパラメーターである必要はありません。 GROUP BYコマンドでは、指定された引数を累積定義式にすることはできません。 この記事では、GROUP BYコマンドを使用して、一連の値から要約された行のセットを作成する方法について説明します。
テーブルの作成:
まず、「Doctor」という名前のテーブルを作成する必要があります。 このテーブルにはさまざまな属性があります。 列には、Doc_id、Doc_fname、Doc_lname、Salary、およびCityが含まれます。 属性にはさまざまなデータ型があります。 列「Doc_id」のデータ型は整数、「Doc_fname」、「Doc_lname」、「City」のデータ型はTEXTです。 一方、属性’Salary’にはNUMERICデータ型が含まれています。
作成 テーブル 医者 ((
Doc_id 整数 主要な 鍵、
Doc_fname TEXT、
Doc_lname TEXT、
給料 NUMERIC、
シティテキスト
)。;
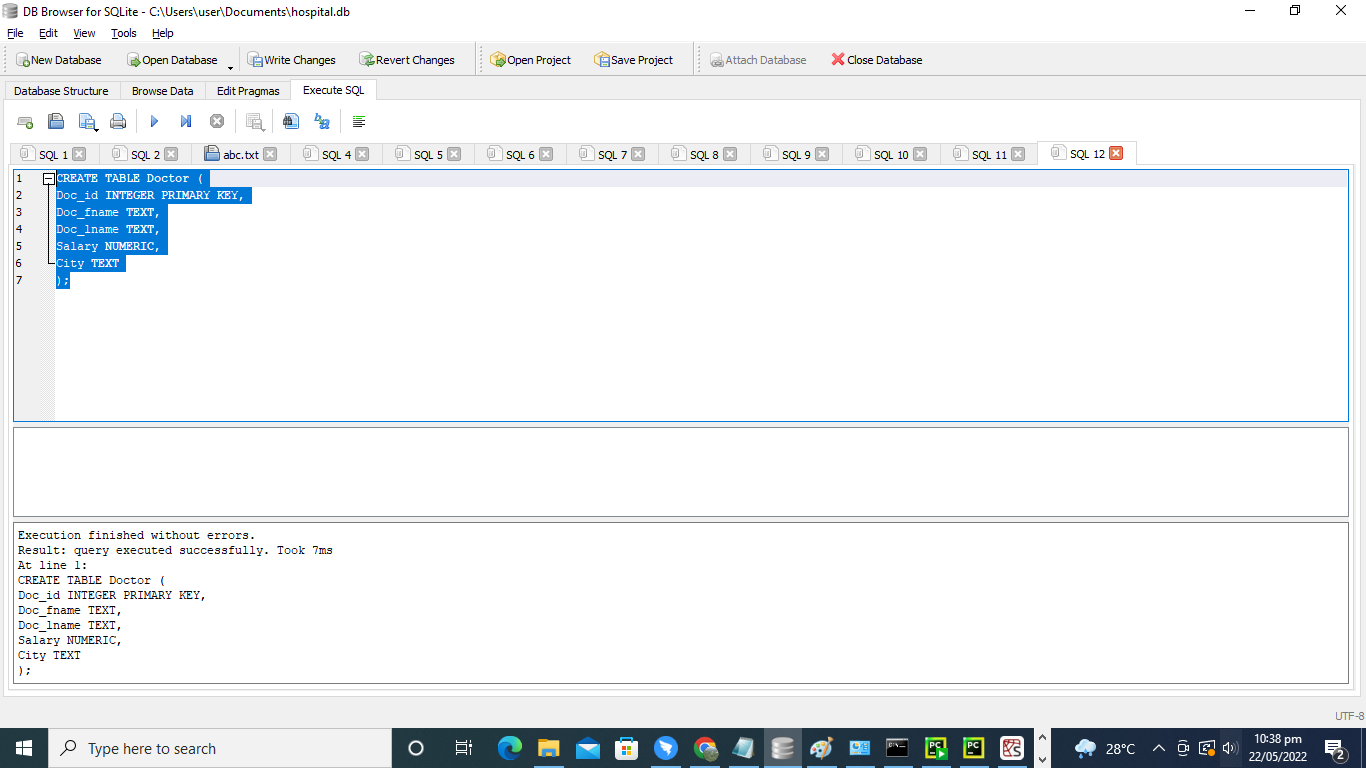
出力には、上記のプログラムの効果的な実行が表示されます。
テーブルを挿入:
次のステップでは、INSERTクエリを使用して、テーブル「Doctor」の列(Doc_id、Doc_fname、Doc_lname、Salary、およびCity)にさまざまな医師のデータを挿入しました。
入れる の中へ 医者 ((Doc_id、 Doc_fname、 Doc_lname、 給料、 街)。 値 ((764、 「喘息」、 「ムニーブ」、 「40000」、 「イスラマバード」)。、
((381、 「ライバ」、 「アジマル」、 ‘90000’、 「スワット」)。、
((904、 「ムハンマド」、 「アーメド」、 「50000」、 「ムルタン」)。、
((349、 「ヌール」、 「ザイン」、 ‘120000’、 「カラチ」)。、
((557、 「カシャーン」、 「ハリド」、 ‘70000’、 「イスラマバード」)。;
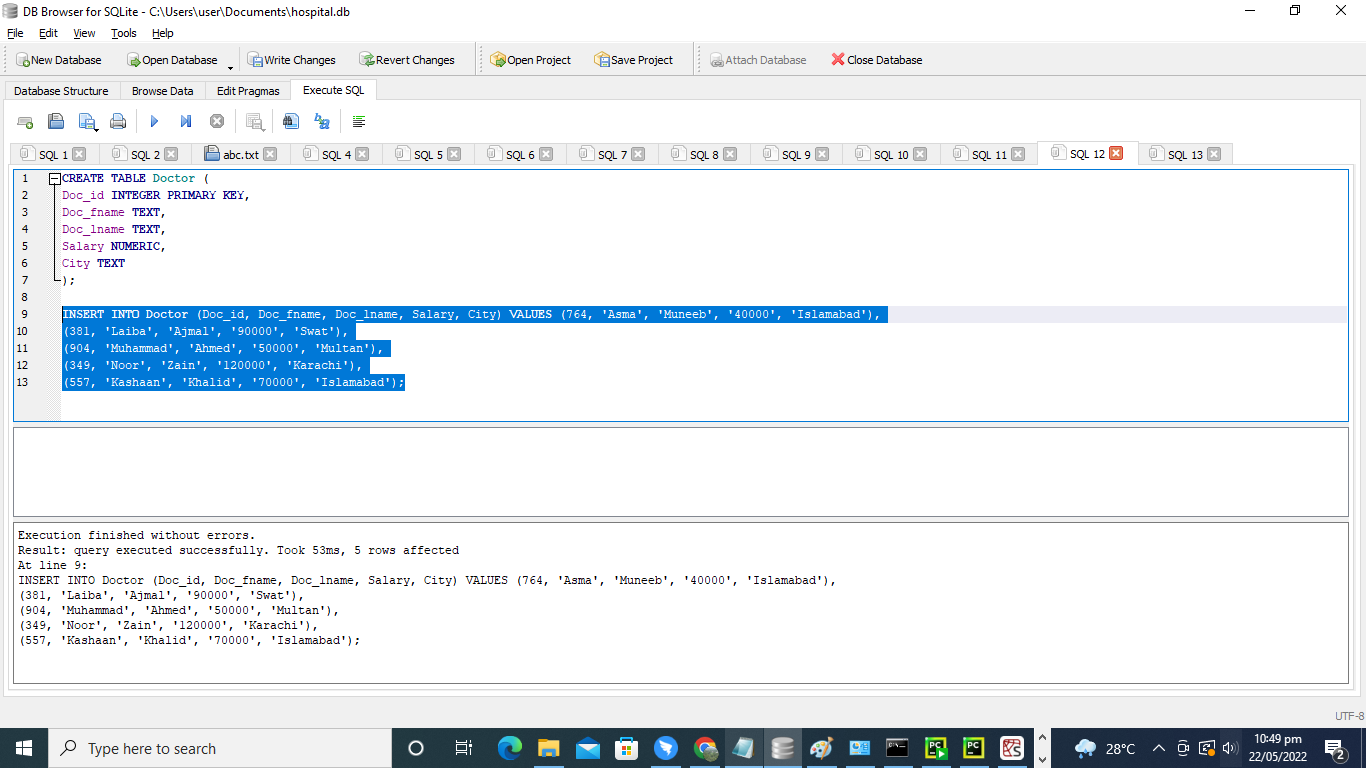
次の図に示すように、INSERTのクエリを正常に実行しました。
SELECTクエリ:
テーブルのデータ全体を取得することも、ほんの数列からデータを取得することもできます。 一部の列の情報を取得する場合は常に、SELECTクエリでその列の名前を指定する必要があります。
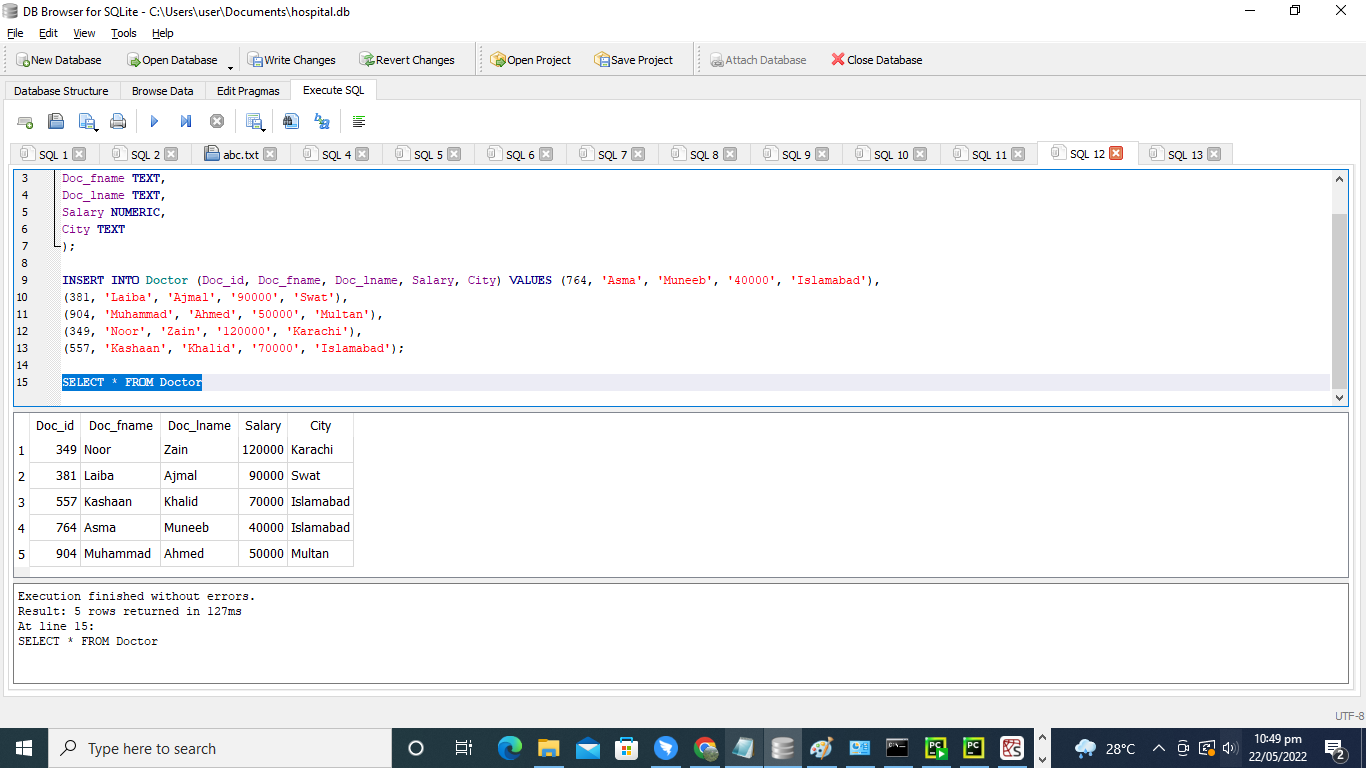
SELECTクエリを実行した後、テーブル’Doctor’のデータ全体を取得します。 この表には、医師のID、名、姓、給与、および都市が含まれています。
GROUPBY句を使用します。
SQLiteクエリでは、GROUP BY句をSELECTコマンドと組み合わせて使用して、同様のデータを整理します。 SELECTクエリでは、GROUP BY句はWHEREステートメントの後、ORDERBYステートメントの直前にあります。 この例では、CityにGROUPBY句を適用しました。
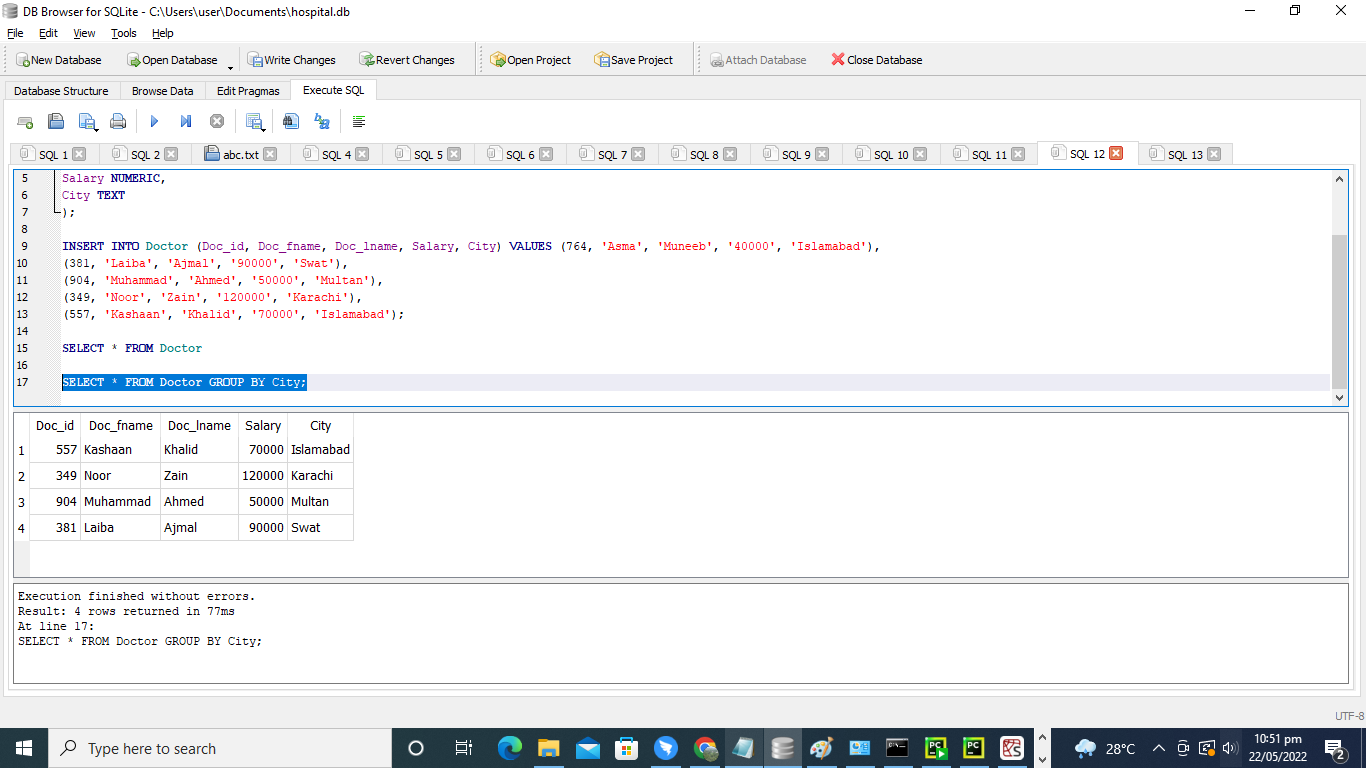
>> 選択する * から 医者 グループ に 街;
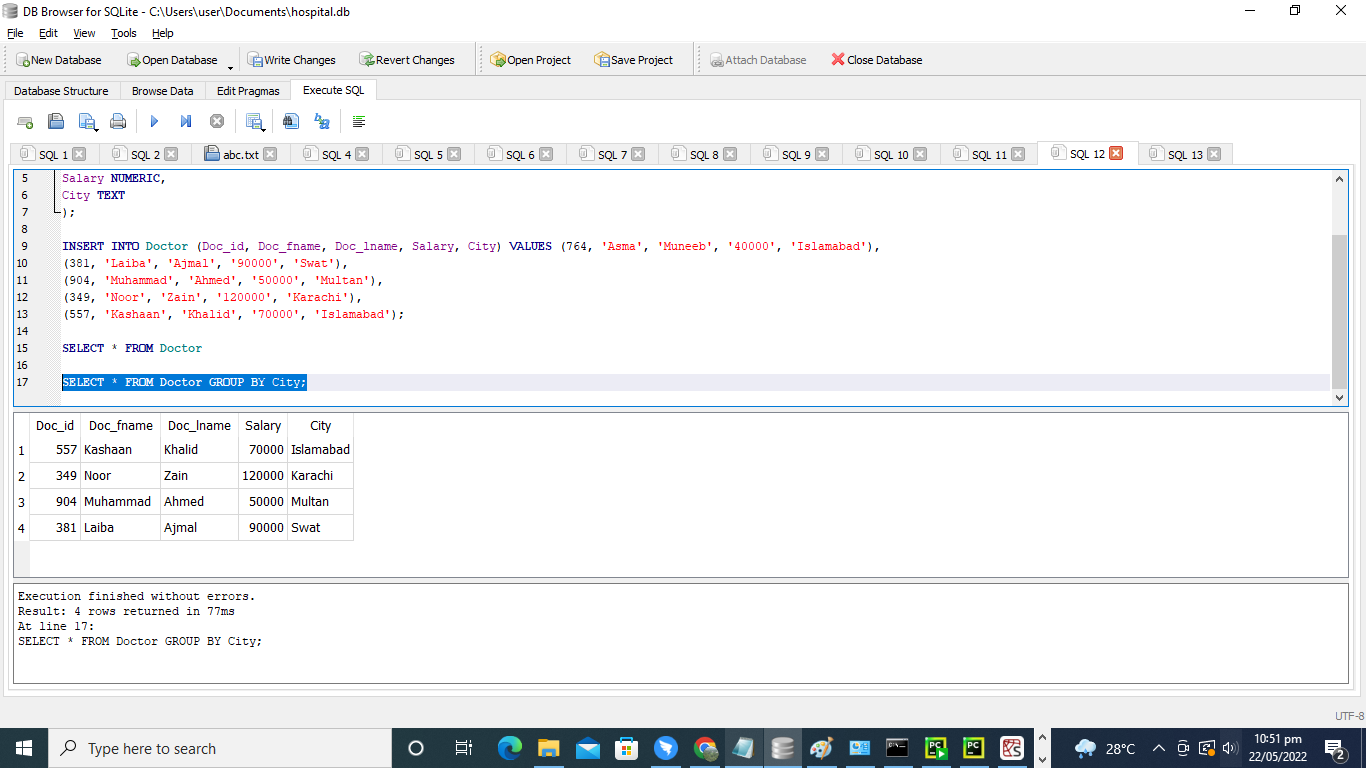
出力のデータは、「City」の列によって集約されます。
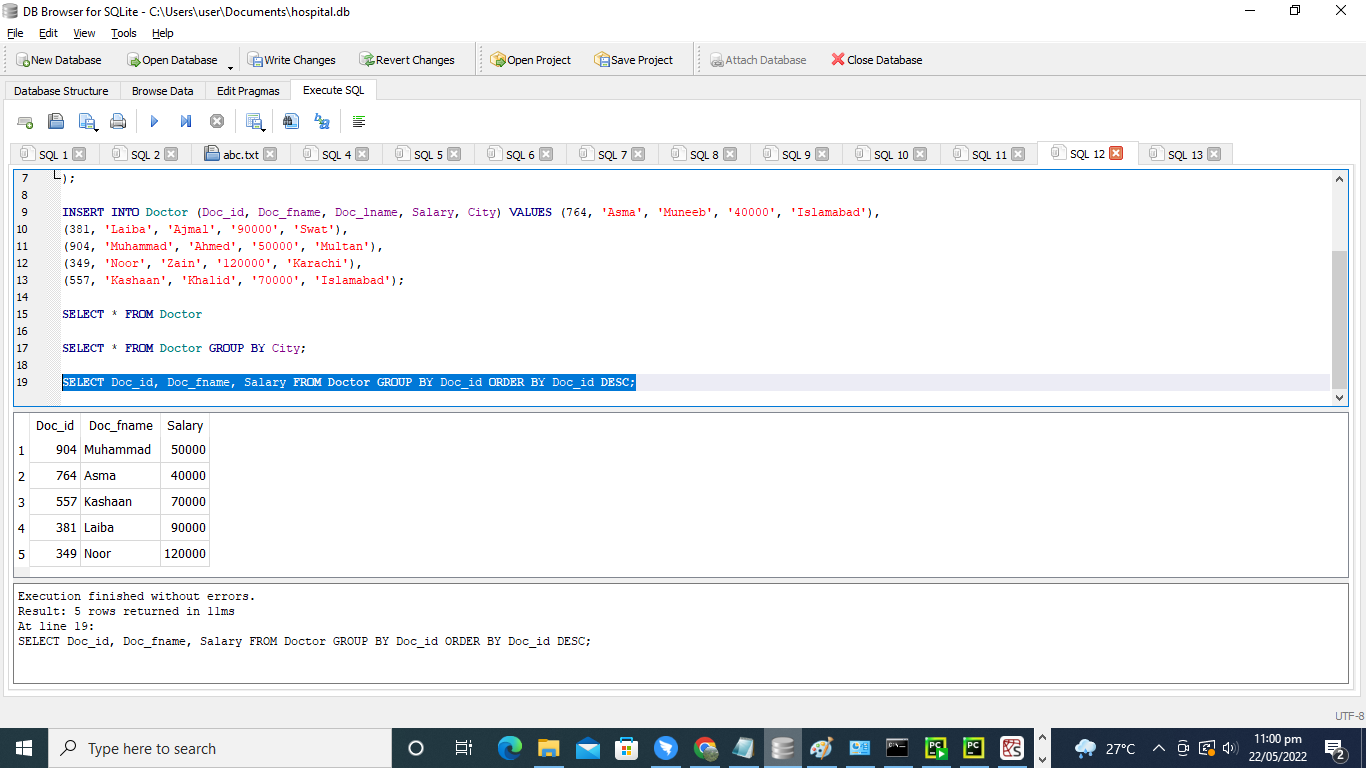
ここでは、医師のID、名、給与のデータを取得したいだけです。 GROUPBY句とORDERBY句は、列「Doc_id」で使用されます。
>> 選択する Doc_id、 Doc_fname、 給料 から 医者 グループ に Doc_id 注文 に Doc_id DESC;
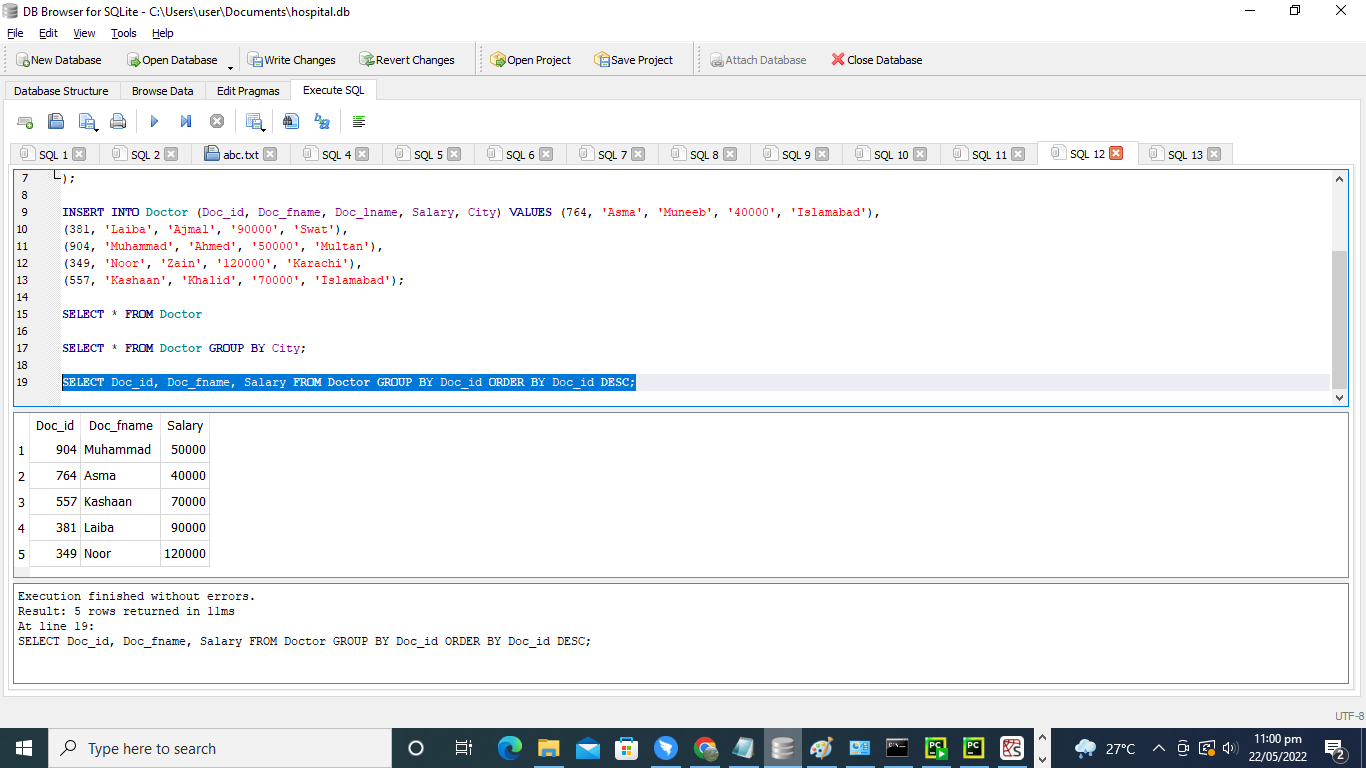
結果のテーブルでは、列「Doc_id」、「Doc_fname」、および給与のデータのみが取得されます。 表のデータは、医師のIDを降順で並べ替えています。
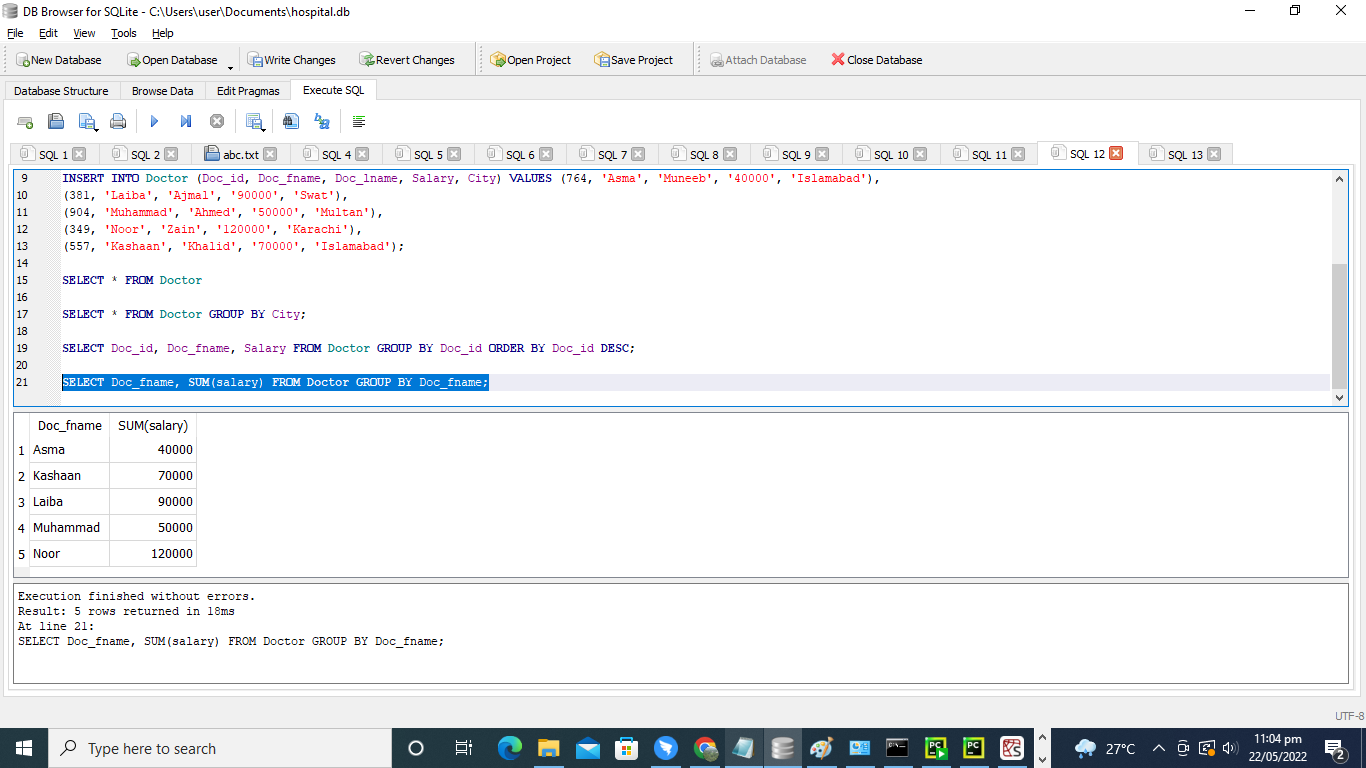
SUMでGROUPBYコマンドを使用します。
テーブル「Doctor」では、SUM関数とともにGroupByステートメントを使用する方法を示します。 すべての医師に支払われる正確な収入額を検討するかどうかにかかわらず、以下に示すようにGROUPBYコマンドを使用します。 ここでは、GROUPBY句が列’Doc_fname’で使用されています。
>> 選択する Doc_fname、 和((給料)。 から 医者 グループ に Doc_fname;
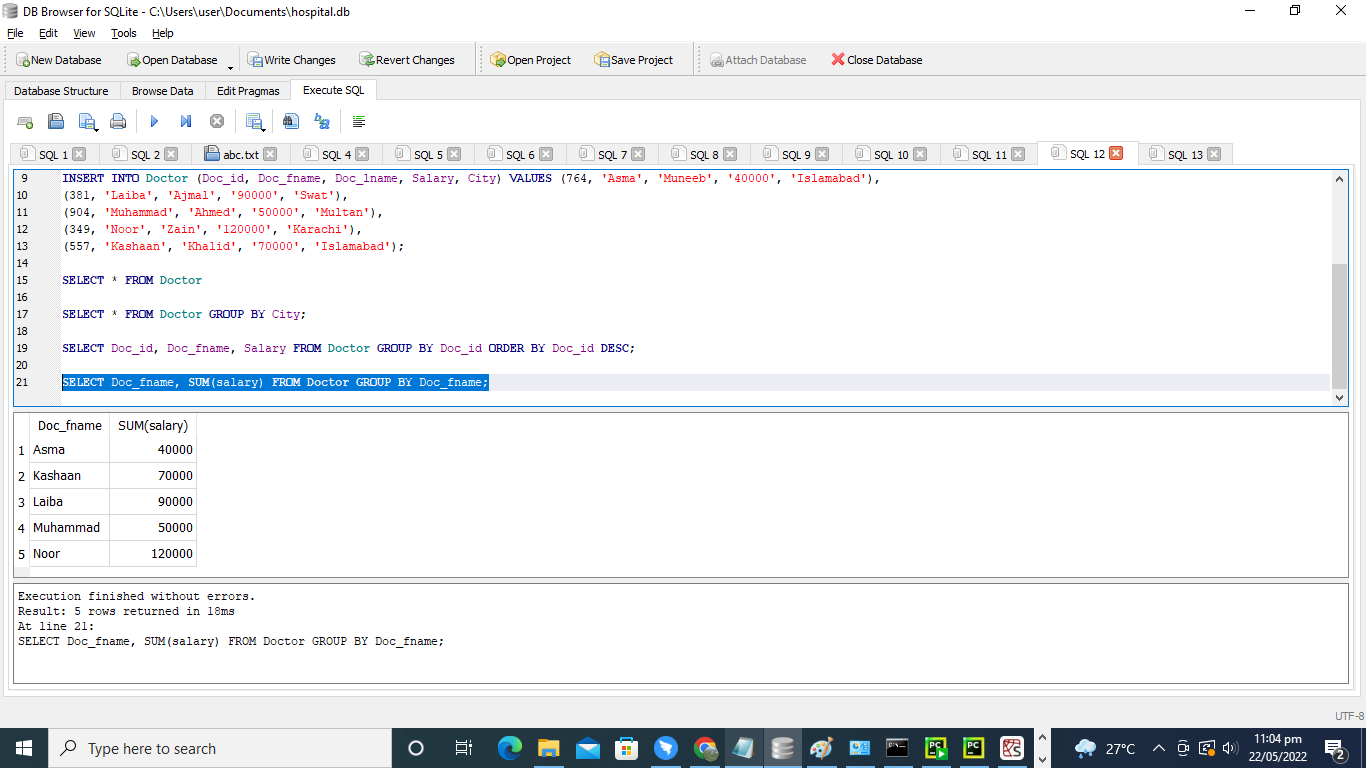
結果のテーブルは、列「Doc_fname」によってグループ化されます。
COUNTでGROUPBYコマンドを使用します。
次のスクリーンショットのようにSELECTステートメントにCOUNT(Doc_lname)を追加するだけで、上記のクエリを少し変更して、COUNTメソッドでGROUPBYコマンドを使用する方法を確認します。
>> 選択する Doc_id、 Doc_fname、 Doc_lname、 給料、 和((給料)。、 カウント((Doc_lname)。 から 医者 グループ に Doc_lname;
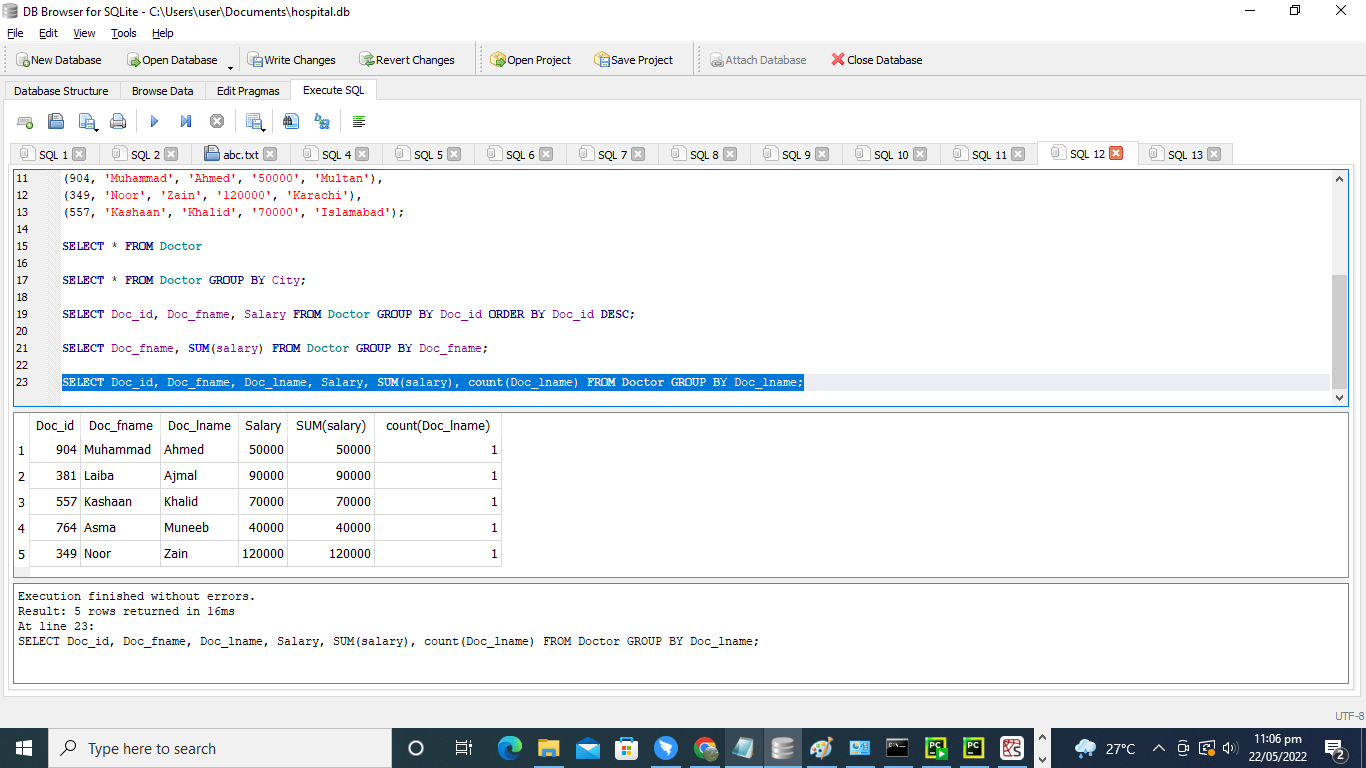
結果を見ると、同じ姓を持つテーブル「Doctor」内の医師の数が計算されます。 すべてのグループの合計を決定するために、SUM関数を使用します。
複数の列に対してGROUPBYコマンドを使用します。
また、いくつかの列にGROUPBYステートメントを使用します。 2つの列にGROUPBYステートメントを使用するインスタンスを見てみましょう。
>> 選択する * から 医者 グループ に 給料、 街;
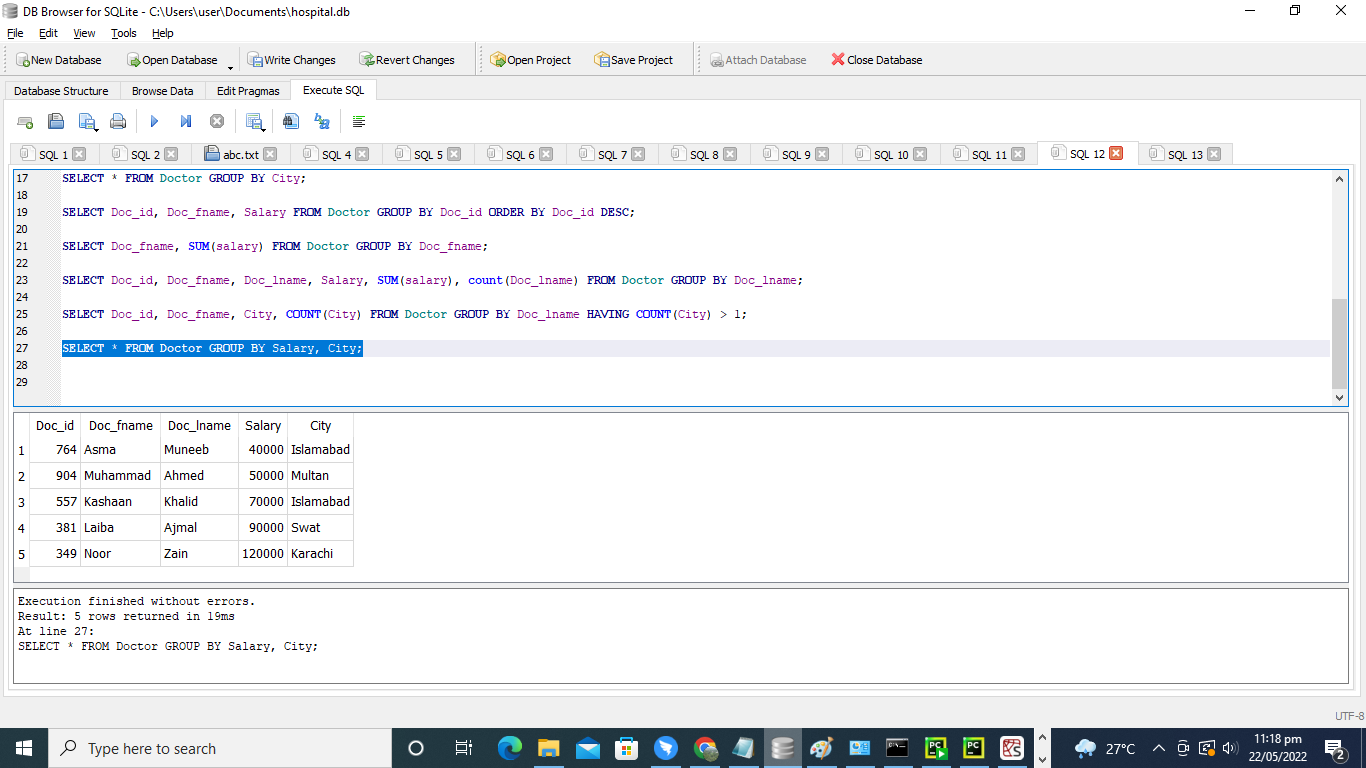
クエリは、テーブル’Doctor’のデータ全体を返します。 GROUP BY句は、給与と市の両方に適用されます。
結論:
いくつかの図の助けを借りて、前の記事でGroupby句をいつどのように利用するかを説明しました。 SQLiteのGROUPBYステートメントは、1つ以上の定義された列の結果が複製される単一のレコード内のデータを結合するために適用されています。 この機能は、個別の列値を検索するだけで検出されるエントリの範囲を減らすために使用されます。 また、Group byステートメントを使用して、ニーズに応じて多数の操作を実行できることにも気づきました。 COUNTおよびSUM関数と一緒にGROUPBYコマンドを利用できます。 また、複数の列にGROUPBYコマンドを使用します。
The post SQLite Group By appeared first on Gamingsym Japan.