
XMLの完全な形式は、eXtensibleMarkupLanguageです。 XMLの各要素またはタグは、ユーザーが定義します。 XMLデータを使用することで、ある場所から別の場所に情報を簡単に送信できます。 XMLデータは階層形式で保存されます。 PostgreSQLデータベースは、XMLデータを格納するためのXMLデータ型をサポートしています。 このチュートリアルでは、PostgreSQLテーブルでXMLデータ型を使用する方法を示しました。
前提条件:
このチュートリアルに示されているSQLステートメントを実行する前に、最新バージョンのPostgreSQLパッケージをLinuxオペレーティングシステムにインストールする必要があります。 次のコマンドを実行して、PostgreSQLをインストールして起動します。
$ sudo systemctl 始める postgresql。サービス
次のコマンドを実行して、root権限でPostgreSQLにログインします。
PostgreSQLデータ型の使用:
ブールデータ型のテーブルを作成する前に、PostgreSQLデータベースを作成する必要があります。 したがって、次のコマンドを実行して、’という名前のデータベースを作成します。testdb‘。
# 作成 データベース testdb;
データベースの作成後、次の出力が表示されます。

A.子ノードが1つあるXMLデータ
次のCREATEクエリを実行して、 xmldoc1 XMLデータ型のフィールドを使用:
# 作成 テーブル xmldoc1 ((xmldata XML)。;
次のINSERTクエリを実行して、XMLデータ型のxmldataフィールドに1つの子ノードを持つXMLデータを追加します。
上記のステートメントを実行すると、次の出力が表示されます。
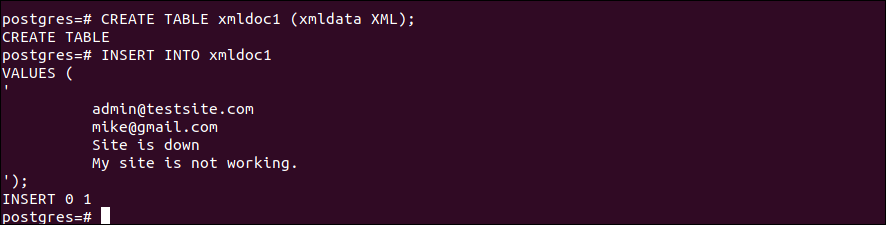
次のSELECTクエリを実行して、からすべてのレコードを読み取ります。 xmldoc1 テーブル:
上記のステートメントを実行すると、次の出力が表示されます。
B.異なる子ノードを持つXMLデータ
次のCREATEクエリを実行して、 xmldoc2 2つのフィールドがあります。 最初のフィールド名は id これはテーブルの主キーです。 このフィールドの値は、新しいレコードが挿入されるときに自動的にインクリメントされます。 2番目のフィールド名はxmldataで、データ型はXMLです。
# 作成 テーブル xmldoc2 ((
idシリアル 主要な 鍵、
xmldata XML )。;
テーブルが正常に作成されると、次の出力が表示されます。

次を実行します 入れる 異なる子ノードのXMLデータを挿入するためのクエリ。 ここでは、4つの子ノードを持つXMLデータがに挿入されます xmldata 分野。
値 ((‘<?xml version = "1.0"?>
<メール>
<から>[email protected]
‘)。;
次の場合、次の出力が表示されます。 入れる クエリは正常に実行されます。

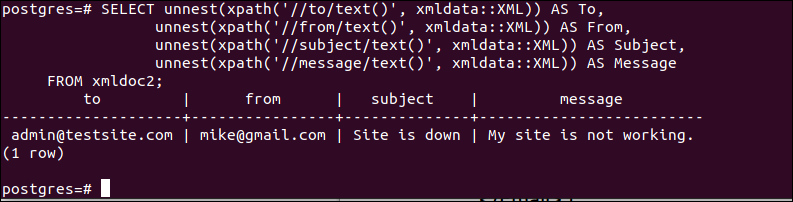
次のSELECTクエリを実行して、各フィールドのXMLドキュメントの各ノードの値を個別に読み取ります。
嫌な((xpath((‘// from / text()’、 xmldata :: XML)。)。 なので から、
嫌な((xpath((‘// subject / text()’、 xmldata :: XML)。)。 なので 主題、
嫌な((xpath((‘// message / text()’、 xmldata :: XML)。)。 なので メッセージ
から xmldoc2;
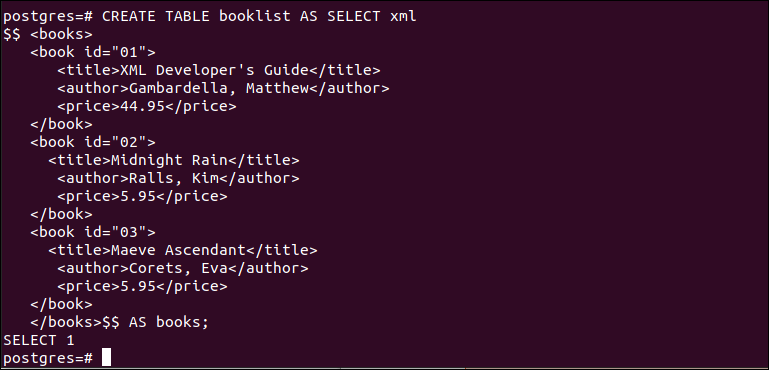
C.XMLデータをテーブルに変換する
次のCREATEクエリを実行して、 ブックリスト XMLデータをテーブルに変換します。
$$<本>>
<ブックID=「01」>>
<題名>>XML開発者ガイド題名>>
<著者>>ガンバルデラ と マシュー著者>>
<価格>>44.95価格>>
本>>
<ブックID=「02」>>
<題名>>真夜中の雨題名>>
<著者>>ラルズ と キム著者>>
<価格>>5.95価格>>
本>>
<ブックID=「03」>>
<題名>>メーブアセンダント題名>>
<著者>>Corets と エヴァ著者>>
<価格>>5.95価格>>
本>>
本>>$$ なので 本;
XMLデータが適切にテーブルに変換されると、次の出力が表示されます。
XMLノードのコンテンツは、ノードのパスを適切に定義することで取得できます。 ザ xmltable。*は、XMLデータから変換されたテーブルからノードと属性の値を読み取る方法の1つです。 次のSELECTクエリを実行して、 id の属性 本 ノードとの値 タイトル、作成者、および価格ノード。 ここでは、「@」記号を使用して属性値を読み取っています。
XMLTABLE ((‘/ books / book’ 合格本
列
id CHAR((2)。 道 ‘@id’ いいえ ヌル、
タイトルテキストパス ‘題名’ いいえ ヌル、
著者テキストパス ‘著者’ いいえ ヌル、
価格 浮く 道 ‘価格’ いいえ ヌル )。;
上記のクエリを実行すると、次の出力が表示されます。

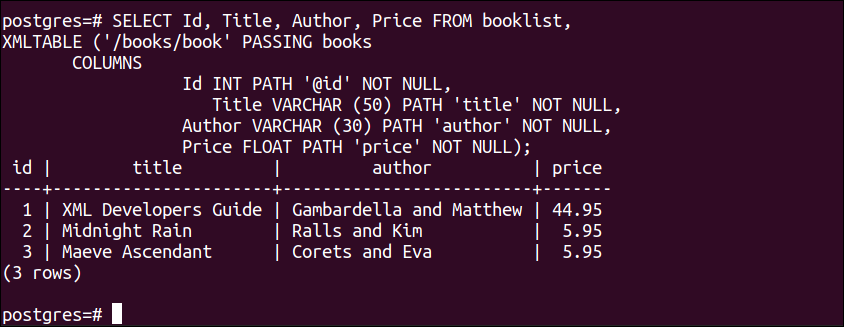
XMLノードと属性の値は、XMLノードに基づいてSELECTクエリでフィールド名を定義することにより、テーブルから取得できます。 次のSELECTクエリを実行して、 id ブックノードの属性との値 タイトル、作成者、および価格ノード。 ここでは、前のSELECTクエリと同様に、「@」記号を使用して属性値を読み取りました。
XMLTABLE ((‘/ books / book’ 合格本
列
Id INT 道 ‘@id’ いいえ ヌル、
題名 VARCHAR ((50)。 道 ‘題名’ いいえ ヌル、
著者 VARCHAR ((30)。 道 ‘著者’ いいえ ヌル、
価格 浮く 道 ‘価格’ いいえ ヌル)。;
上記のクエリを実行すると、次の出力が表示されます。
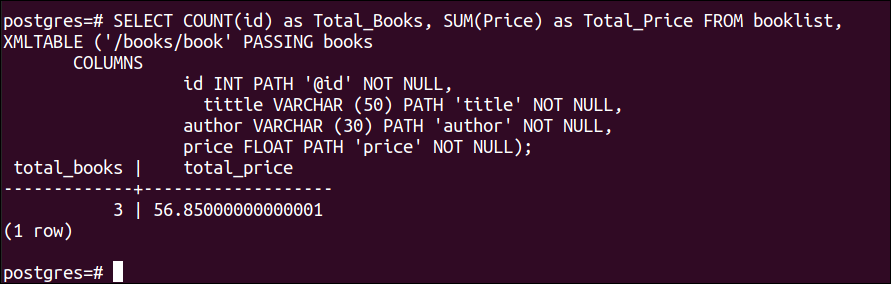
集計関数は、SELECTクエリを使用してXMLのノードに適用できます。 次のSELECTクエリを実行して、 id を使用したすべての書籍の属性と合計価格 COUNT()関数とSUM() 関数。 XMLデータによると、id属性の総数は3であり、すべての価格ノードの合計は56.85です。
XMLTABLE ((‘/ books / book’ 合格本
列
id INT 道 ‘@id’ いいえ ヌル、
タイトル VARCHAR ((50)。 道 ‘題名’ いいえ ヌル、
著者 VARCHAR ((30)。 道 ‘著者’ いいえ ヌル、
価格 浮く 道 ‘価格’ いいえ ヌル)。;
上記のクエリを実行すると、次の出力が表示されます。
結論:
このチュートリアルでは、PostgreSQLテーブルでXMLデータ型を使用し、テーブルからXMLデータをさまざまな方法で読み取る方法を示し、新しいPostgreSQLユーザーがこのデータ型の使用法を正しく理解できるようにします。
The post PostgreSQLXMLデータ型 appeared first on Gamingsym Japan.