
「「MongoDBデータベースは、データの保存と操作において重要な役割を果たします。 データを整理するために、同じ種類のデータを1か所に集めるグループを作成します。 グループ化は、カウント変数またはその他の機能のいずれからでも、さまざまな属性で行うことができます。 このチュートリアルでは、ドキュメントのさまざまなフィールドに応じたグループの作成について説明します。
複数のフィールドに応じたグループの現象を実装するには、データベースにいくつかのデータが必要です。 最初にデータベースを作成します。 これは、キーワード「use」を使用してデータベースの名前を宣言することによって行われます。 この実装では、データベース「デモ」を使用しています。
データベースの作成が完了すると、データがデータベースに挿入されます。 また、「コレクション」を作成するために使用したデータエントリの場合、これらは無制限のデータを格納する上で重要な役割を果たすコンテナです。 一度に、1つのデータベースに多数のコレクションを作成できます。 ここでは、「info」という名前のデータベースを作成します。
>> Db。createCollection((‘情報’)。
MongoDBの応答は「ok」になります。 コレクションの作成の確認です。 コレクション内のデータは行ごとに入力されます。 そのため、コレクションにデータを挿入します。 このデータは、さまざまなフィールドに従ってグループを作成するための例でさらに使用されるため、多くの行を入力しました。 各行に異なるIDが割り当てられるたび。
>> db。情報。insertOne (({{“名前” : 「サビッド」、
“年” : 28、
“性別” : “男”、
“国”: “アメリカ合衆国”})。
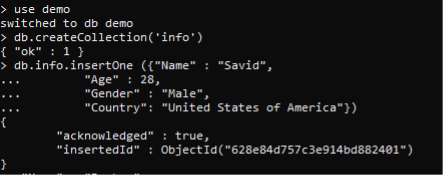
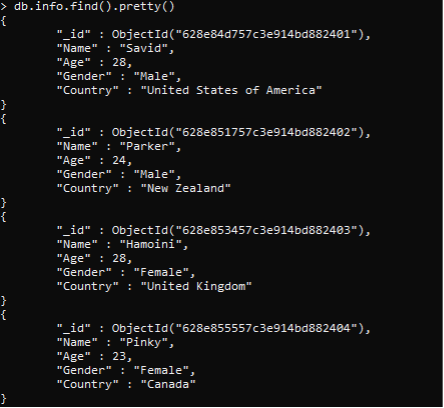
同様に、すべてのデータが挿入されます。 find()コマンドを使用して、挿入されたすべてのデータを表示できます
>> db。情報。探す(()。。かわいい(()。
例1:複数のフィールド/属性でグループ化
データベースに大量のデータセットがあるが、それらのいくつかを表示したい場合、この目的のために、$groupsが見つかります。 この例では、コレクションからいくつかの特定の属性を表示するグループを作成します。 グループ係数は、集計操作に依存します。 集計操作を使用して、共通フィールドに従ってデータを合計します。 ドルの「$」記号は変数を示します。 次に、上記の情報コレクションにクエリを適用します。
IDに応じたグループが作成されます。 次に、年齢と性別のドキュメントのみが選択されて表示されます。 一方、名前と国を含むデータ全体が削除されます。 これはどういうわけか、データの表示を制限するために使用されるフィルターです。
>> db。情報。集計(([ {$group: {_id: {age:“$Age”, gender:“$Gender”} } } ])。
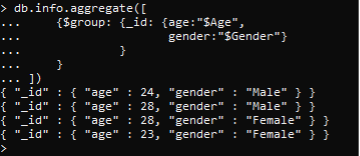
データを2つの属性に制限することにより、idに従って各行をグループ化したことがわかります。
例2:条件を適用して複数のフィールドをグループ化する
これは、特定の条件に従ってドキュメントをグループ化することを指します。 グループは2つの属性で作成され、グループの作成後に、特定のドキュメントの値の出現をカウントするためのカウント変数を追加します。 また、並べ替え順序を追加しました。
まず、コレクション内のドキュメントを「新規」で表示しましょう。 上記と同じ手順に従って、コレクションを作成し、以前にデータを追加しました。 find()関数を使用して、コレクション内のすべてのアイテムのみを表示します。
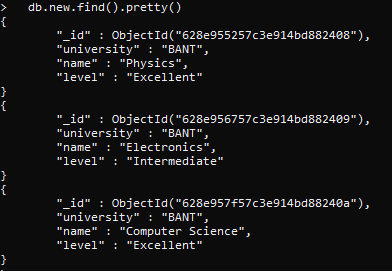
クエリには、最初にグループ部分が含まれます。 グループはidで作成されます。 大学とレベルは、表示したい2つの基本的な属性です。 使用する変数は、コレクションから値を取得し、それをクエリ変数に割り当てます。 すべての値と条件がコマンドに直接書き込まれるわけではありません。
グループの作成後、条件が適用されます。 各ドキュメントのレベルに応じて合計を数え、計算することです。 その後、この回答は降順で並べられます。 これは、sort()関数を介して行われます。 この関数には2つのパラメーターのみが含まれています。 昇順の場合は1、降順の場合は-1です。
>> db。新着。集計(([ {$group:{ _id:{ “university”:“$university”, “level”:“$level” }, “levelCount”:{“$sum”:1} }}, {“$sort”:{“levelCount”:–1}} ])。
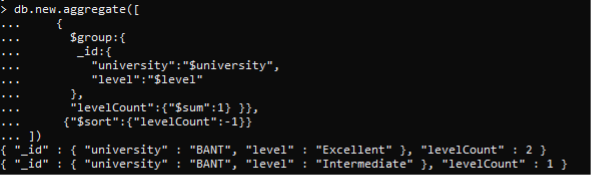
降順では、レベルの大きい方が最初に表示され、次に小さい方がレベルドキュメントの後に表示されます。
例3:複数のフィールドによるMongoDbBUCKETグループ
名前が示すように、グループはバケットに従って検出されます。 これは、バケット集計を作成することによって行われます。 バケット集約は、ドキュメントをグループに分類するプロセスです。 このグループはバケツのように機能します。 各ドキュメントは、特定の表現に応じて分割されます。
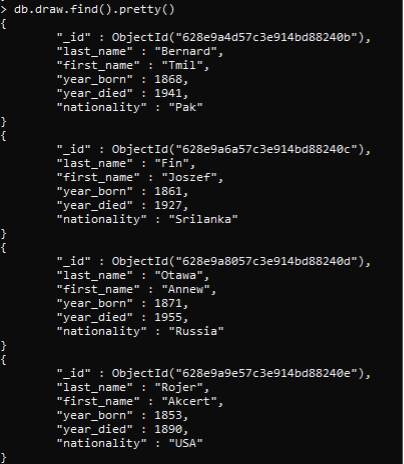
この概念を詳しく説明するために、作成したコレクションを見てから、それにコマンドを適用します。 人に関する基本情報を格納する「描画」コレクションが作成されます。 以前にコレクションに入力された4行すべてを表示しました。
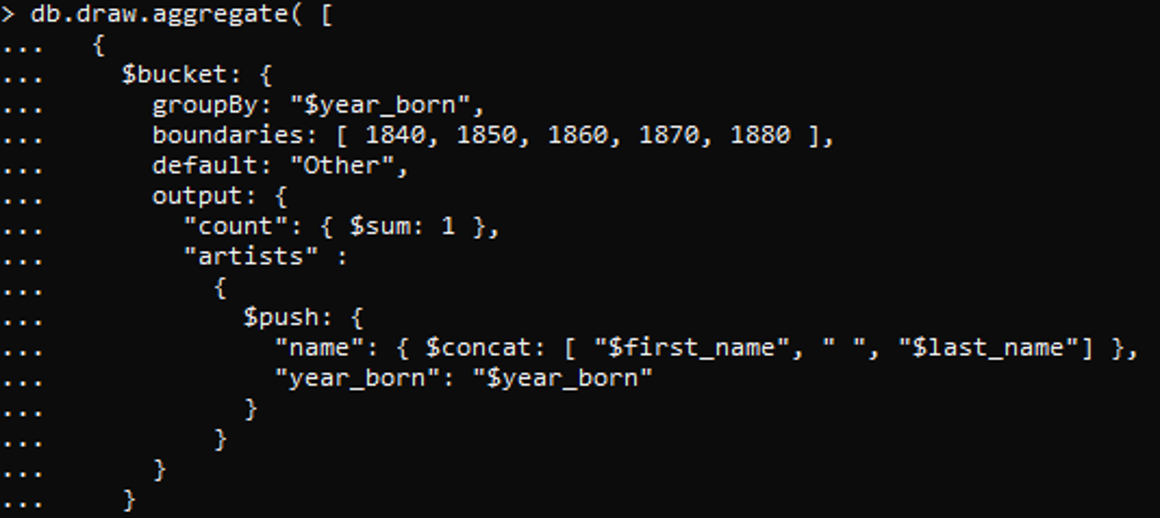
上記のデータに、データをグループ化するための属性として年を持つバケット(グループ)を作成するコマンドを適用します。 また、生まれた年と死んだ年が記載された境界線を作成しました。 このコマンドに適用される条件には、発生数をカウントするためのカウント変数が含まれます。 また、ここでは連結メソッドを使用して、名と2番目の名前の両方を文字列として結合しました。 また、生年月日が表示されます。 IDは年によって異なります。
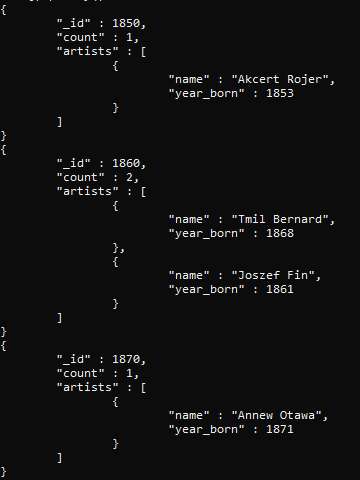
このクエリを計算すると、結果の値は、作成した年齢境界に応じて2つの行がグループ化されていることを示します。
結論
この記事では、複数のフィールドに依存するグループ化のMongoDB機能について、グループ作成での集約操作の動作を示すことで詳しく説明します。 集約機能がないと、グループ機能は不完全です。 グループ機能は、データ全体の公開を制限するために、さまざまなフィールドを介して直接適用されます。 複数のフィールドを介したグループ化も、特定の条件を適用することによって実現されます。 最後に、バケットのようなより多くのアイテムを含むバケットグループの作成について説明しました。
The post 複数のフィールドによるMongoDBグループ appeared first on Gamingsym Japan.