
「挿入、更新、検索、削除、および集計は、標準のコレクションの場合と同様に、時系列コレクションで実行できるすべての操作です。 カーテンの後ろには、根本的な違いがあります。 MongoDBにデータを挿入すると、最適なストレージ形式に変換されます。 時系列は、通常のコレクションよりも単純でクエリ効率が高くなります。
時系列コレクションは、MongoDBではマテリアライズされていない書き込み可能なビューとして扱われます。 データはより効率的に保存され、ディスクスペースを節約し、時間ベースの内部インデックスが自動的に作成されます。 データを圧縮するために、snappyの代わりにzstdアルゴリズムがデフォルトで使用されます。 新しい圧縮は比率が高く、必要なCPUパワーが少なく、ドキュメント間のわずかな違いがある時系列分析に特に適しています。
将来的に圧縮アルゴリズムを変更することは可能ですが、これは推奨されていません。 ドキュメントを挿入すると、時系列コレクションは他のコレクションのように自動的に作成されません。 明示的に作成する必要があります。」
Ubuntu 20.04のMongoDBの時系列とは何ですか?
時系列データベースは、タイムスタンプと効率的に結合された値の一定のストリームから作成されたデータを格納するために構築されたカスタマイズされたデータベースです。 最も一般的なアプリケーションは、一定の間隔でデータポイントを配信するセンサー機器からのデータを保存することですが、現在では、はるかに幅広いアプリケーションに対応するために使用されています。
考えられるアプリケーションの例を次に示します。
- モノのインターネットからのデータ
- Webサービス、アプリ、インフラストラクチャはすべて常に監視されています。
- 売上の見積もり
- 財務動向の理解
- 自動運転車やその他の物体からのデータが処理されています。
時系列の特殊データベースは、圧縮テクノロジーを使用して必要なスペースの量を削減すると同時に、データをより深く掘り下げるためのアクセスチャネルを提供します。 これにより、時間範囲フィルターを使用する場合のデータ取得と集計のパフォーマンスが向上します。 これらは、従来のリレーショナルデータベースを利用するよりも費用効果が高くなります。
時系列の値は、通常、記録された後は変更されません。 したがって、これらはINSERTのみまたは不変のデータポイントとして指定されます。 データが保存された後の更新アクションは非常にまれです。
Ubuntu20.04でのMongoDB時系列データストレージのガイドライン
MongoDBの時系列データに関するガイドラインがいくつかあります。以下にその概要を示します。
- 適切なmetaFieldとtimeFieldに合わせてデータを調整しながら、データ機能とクエリパターンを検討してください。
- 可能であれば、時系列データと時系列コレクションを組み合わせます。
- 時系列コレクションを利用する場合は、個々の測定値または測定値のセットを1つのドキュメントとして保存し、バッチで追加する必要があります。
- データの取り込みペースに基づいて、metaFieldの属性値、または一意のmetaFieldの個別の組み合わせに関するデータの粒度をカスタマイズします。
Ubuntu20.04で時系列MongoDBを使用する方法
時系列データを操作する場合、通常は単なるストレージ以上のものが必要です。 また、高速の読み取りおよび書き込み機能と高度なクエリ機能も必要です。 MongoDB 5.0以降、MongoDBは時系列データをネイティブに処理するようになりました。 MongoDBで時系列コレクションを提供する場合は、次のオプションを指定する必要があります。
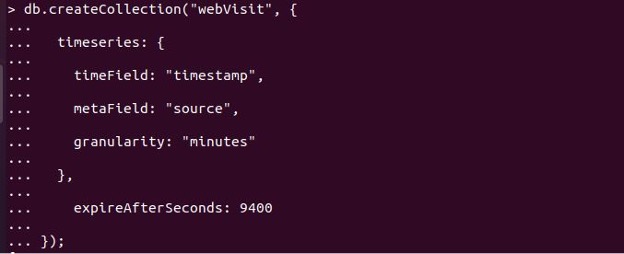
createCollection()コマンドを使用して、新しい時系列コレクションを開始できます。
timeField: 時系列コレクションを作成するときは、timeFieldオプションを使用する必要があります。 timeFieldは、日付を含む各ドキュメントのプロパティの説明を示します。 次の代替案も検討する必要があります。
metaField: metaFieldは、メタデータを含む各ドキュメントの列の名前を指定します。 metaFieldは、時系列コレクションが時系列のソースを識別できるようにするラベルまたはタグとして機能します。 このフィールドは、時間の経過とともに変化するべきではなく、変化するだけです。
粒度: 一致するmetaFieldが指定されている場合、粒度属性はドキュメント間の時間的なギャップを指定します。 標準の粒度は「秒」であり、metaFieldによって定義された各時系列の高周波摂取率を示します。 粒度は「秒」、「分」、または「時間」に調整でき、悪化させるためにいつでも変更できます。 ただし、粒度を「分」から「秒」に変更することはできないため、より細かい粒度から始めて、より厳しい粒度に進むことをお勧めします。
ExpireAfterSeconds: 最後に、指定した期間後にデータを削除する場合は、expireAfterSecondsフィールドに、ドキュメントの有効期限が切れて自動的に破棄されるまでに経過する秒数を指定できます。
MongoDBに時系列のドキュメントを挿入する
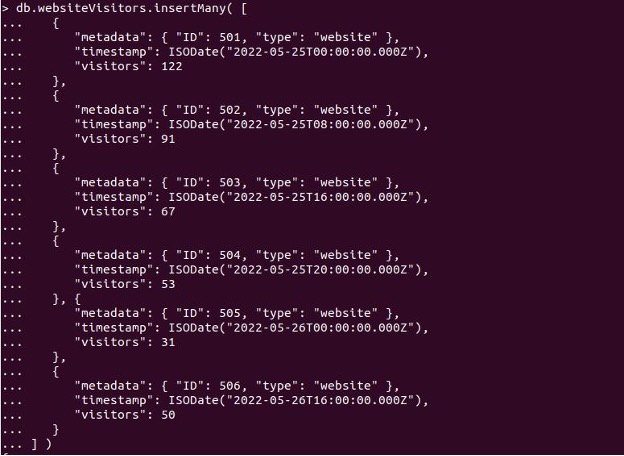
少なくとも、時系列コレクションに追加される各ドキュメントは、timeFieldを定義する必要があります。 日付は、以下のイラストドキュメントのtimeFieldです。 timeFieldは、BSONタイプまたはDateである限り、任意の名前を付けることができることに注意してください。 ドキュメントを他のMongoDBコレクションに挿入するための任意の手法を使用して、ドキュメントを時系列コレクションに追加できます。 このために、次のように「webVisitors」のコレクションを作成しました。

挿入する各ドキュメントには、単一の測定値を含める必要があります。 次のコマンドを使用して、一度に多くのドキュメントを挿入します。
Ubuntu20.04のMongoDBで時系列データを取得する
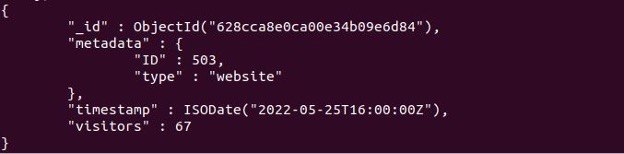
時系列ドキュメントは、MongoDBの他のコレクションのドキュメントと同じようにクエリできます。 たとえば、MongoDBシェルでは、次のようにfindOneを使用してwebVisitors collection()でドキュメントを検索しました。

ご覧のとおり、上記のクエリは次の結果を示しています。
Ubuntu20.04のMongoDBでの時系列データの集計
ここでは、クエリ機能を追加するなどの集約パイプラインを使用しました。 次の集計パイプラインの例は、測定データによってすべてのドキュメントを結合し、Webサイトのその日に行われたすべての訪問者の測定値の平均を提供します。
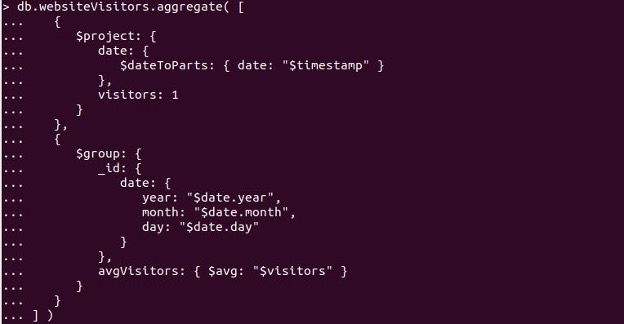
コレクションwebsiteVisitorsで集計パイプラインを実行すると、出力はコレクション「websiteVisitors」からの訪問者のドキュメントの平均を次のように生成しました。

結論
時系列データはたくさんありますが、それを維持してアクセスするのは難しい場合があります。 MongoDBは時系列のネイティブサポートを取得し、時系列データの操作を大幅に簡単、高速、低コストにしました。 MongoDBで時系列を使用するためのいくつかのガイドラインを含む簡単な紹介をしました。 MongoDBコレクションで時系列をいくつかの可能な方法で使用する方法を示す時系列の図がいくつかあります。
The post 時系列でMongoDBを使用する方法 appeared first on Gamingsym Japan.