
Pythonでは、PySparkはDataFrameを使用したsparkのような同様の種類の処理を提供するために使用されるSparkモジュールです。 この記事では、PySparkDataFrameを作成するいくつかの方法について説明します。
方法1:辞書を使用する
ディクショナリは、データをキーと値のペアの形式で格納するデータ構造です。
PySpark DataFrameでは、キーは列として機能し、値は行の値/データとして機能します。 これはリスト内で渡す必要があります。
構造:
複数の辞書を提供することもできます。
構造:
[{‘key’ : value},{‘key’ : value},…….,{‘key’ : value}]
例:
ここでは、ディクショナリを介して5行6列のPySparkDataFrameを作成します。 最後に、show()メソッドを使用してDataFrameを表示しています。
pysparkをインポートする
セッションを作成するための#importSparkSession
pyspark.sqlからインポートSparkSession
#linuxhintという名前のアプリを作成します
spark_app = SparkSession.builder.appName((‘linuxhint’)。.getOrCreate(()。
#5行6属性の学生データを作成する
学生=[{‘rollno’:’001’,’name’:’sravan’,’age’:23,’height’:5.79,’weight’:67,’address’:’guntur’},
{‘rollno’:’002’,’name’:’ojaswi’,’age’:16,’height’:3.79,’weight’:34,’address’:’hyd’},
{‘rollno’:’003’,’name’:’gnanesh chowdary’,’age’:7,’height’:2.79,’weight’:17,’address’:’patna’},
{‘rollno’:’004’,’name’:’rohith’,’age’:9,’height’:3.69,’weight’:28,’address’:’hyd’},
{‘rollno’:’005’,’name’:’sridevi’,’age’:37,’height’:5.59,’weight’:54,’address’:’hyd’}]
#データフレームを作成する
df = spark_app.createDataFrame(( 学生)。
#データフレームを表示する
df.show(()。
出力:

方法2:タプルのリストを使用する
タプルは、データを()に格納するデータ構造です。
リストで囲まれたタプルで、コンマで区切られた行を渡すことができます。
構造:
[(value1,value2,.,valuen)]
リストに複数のタプルを提供することもできます。
構造:
[(value1,value2,.,valuen), (value1,value2,.,valuen), ………………,(value1,value2,.,valuen)]
DataFrameを作成するときに、リストを介して列名を指定する必要があります。
構文:
spark_app.createDataFrame(( list_of_tuple、column_names)。
例:
ここでは、ディクショナリを介して5行6列のPySparkDataFrameを作成します。 最後に、show()メソッドを使用してDataFrameを表示しています。
pysparkをインポートする
セッションを作成するための#importSparkSession
pyspark.sqlからインポートSparkSession
#linuxhintという名前のアプリを作成します
spark_app = SparkSession.builder.appName((‘linuxhint’)。.getOrCreate(()。
#5行6属性の学生データを作成する
学生=[(‘001’,‘sravan’,23,5.79,67,‘guntur’),
(‘002’,‘ojaswi’,16,3.79,34,‘hyd’),
(‘003’,‘gnanesh chowdary’,7,2.79,17,‘patna’),
(‘004’,‘rohith’,9,3.69,28,‘hyd’),
(‘005’,‘sridevi’,37,5.59,54,‘hyd’)]
#列名を割り当てる
column_names = [‘rollno’,‘name’,‘age’,‘height’,‘weight’,‘address’]
#データフレームを作成する
df = spark_app.createDataFrame(( 学生、column_names)。
#データフレームを表示する
df.show(()。
出力:
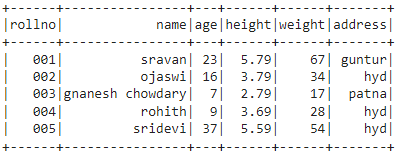
方法3:リストのタプルを使用する
リストは、データを格納するデータ構造です。 []。
タプルで囲まれたリストで、コンマで区切られた行を渡すことができます。
構造:
(([value1,value2,.,valuen])。
タプルで複数のリストを提供することもできます。
構造:
(([value1,value2,.,valuen]、 [value1,value2,.,valuen]、………………、[value1,value2,.,valuen])。
DataFrameを作成するときに、リストを介して列名を指定する必要があります。
構文:
spark_app.createDataFrame(( tuple_of_list、column_names)。
例:
ここでは、ディクショナリを介して5行6列のPySparkDataFrameを作成します。 最後に、show()メソッドを使用してDataFrameを表示しています。
pysparkをインポートする
セッションを作成するための#importSparkSession
pyspark.sqlからインポートSparkSession
#linuxhintという名前のアプリを作成します
spark_app = SparkSession.builder.appName((‘linuxhint’)。.getOrCreate(()。
#5行6属性の学生データを作成する
学生=(([‘001’,‘sravan’,23,5.79,67,‘guntur’]、
[‘002’,‘ojaswi’,16,3.79,34,‘hyd’]、
[‘003’,‘gnanesh chowdary’,7,2.79,17,‘patna’]、
[‘004’,‘rohith’,9,3.69,28,‘hyd’]、
[‘005’,‘sridevi’,37,5.59,54,‘hyd’])。
#列名を割り当てる
column_names = [‘rollno’,‘name’,‘age’,‘height’,‘weight’,‘address’]
#データフレームを作成する
df = spark_app.createDataFrame(( 学生、column_names)。
#データフレームを表示する
df.show(()。
出力:
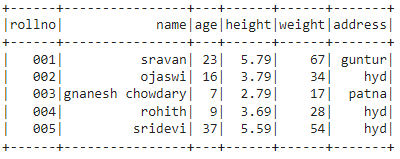
方法4:ネストされたリストを使用する
リストは、データを格納するデータ構造です。 []。
したがって、リストで囲まれたリストで、コンマで区切られた行を渡すことができます。
構造:
[[value1,value2,.,valuen]]
1つのリストに複数のリストを提供することもできます。
構造:
[[value1,value2,.,valuen]、 [value1,value2,.,valuen]、………………、[value1,value2,.,valuen]]
DataFrameを作成するときに、リストを介して列名を指定する必要があります。
構文:
spark_app.createDataFrame(( 入れ子リスト、列名)。
例:
ここでは、ディクショナリを介して5行6列のPySparkDataFrameを作成します。 最後に、show()メソッドを使用してDataFrameを表示しています。
pysparkをインポートする
セッションを作成するための#importSparkSession
pyspark.sqlからインポートSparkSession
#linuxhintという名前のアプリを作成します
spark_app = SparkSession.builder.appName((‘linuxhint’)。.getOrCreate(()。
#5行6属性の学生データを作成する
学生=[[‘001’,‘sravan’,23,5.79,67,‘guntur’]、
[‘002’,‘ojaswi’,16,3.79,34,‘hyd’]、
[‘003’,‘gnanesh chowdary’,7,2.79,17,‘patna’]、
[‘004’,‘rohith’,9,3.69,28,‘hyd’]、
[‘005’,‘sridevi’,37,5.59,54,‘hyd’]]
#列名を割り当てる
column_names = [‘rollno’,‘name’,‘age’,‘height’,‘weight’,‘address’]
#データフレームを作成する
df = spark_app.createDataFrame(( 学生、column_names)。
#データフレームを表示する
df.show(()。
出力:
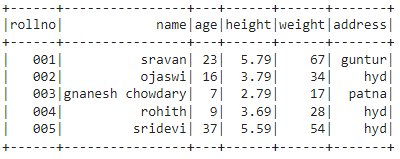
方法5:ネストされたタプルを使用する
構造:
((((value1、value2、。、valuen)。)。
タプルに複数のタプルを提供することもできます。
構造:
((value1、value2、。、valuen)、(value1、value2、。、valuen)、………………、(value1、value2、。、valuen))
DataFrameを作成するときに、リストを介して列名を指定する必要があります。
構文:
spark_app.createDataFrame(( ネストされたタプル、列名)。
例:
ここでは、ディクショナリを介して5行6列のPySparkDataFrameを作成します。 最後に、show()メソッドを使用してDataFrameを表示しています。
pysparkをインポートする
セッションを作成するための#importSparkSession
pyspark.sqlからインポートSparkSession
#linuxhintという名前のアプリを作成します
spark_app = SparkSession.builder.appName((‘linuxhint’)。.getOrCreate(()。
#5行6属性の学生データを作成する
学生=((((‘001’、「スラバナ」、23、5.79、67、「グントゥール」)。、
((‘002’、‘ojaswi’、16、3.79、34、‘hyd’)。、
((‘003’、‘gnanesh chowdary’、7、2.79、17、「パトナ」)。、
((‘004’、‘rohith’、9、3.69、28、‘hyd’)。、
((‘005’、‘sridevi’、37、5.59、54、‘hyd’)。)。
#列名を割り当てる
column_names = [‘rollno’,‘name’,‘age’,‘height’,‘weight’,‘address’]
#データフレームを作成する
df = spark_app.createDataFrame(( 学生、column_names)。
#データフレームを表示する
df.show(()。
出力:
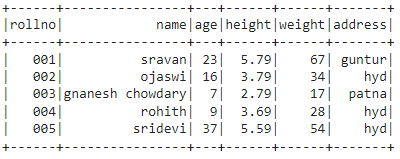
結論
このチュートリアルでは、PySpark DataFrameを作成するための5つの方法について説明しました。タプルのリスト、リストのタプル、ネストされたタプル、ネストされたリストの使用、および列名を提供する列リストです。 ディクショナリを使用してPySparkDataFrameを作成するときに、列名リストを提供する必要はありません。
The post PySparkDataFrameを作成するさまざまな方法 appeared first on Gamingsym Japan.