
前回、前々回の記事で、Pythonを使った文書の要約について紹介致しました。
これは、長文から重要な部分を抜き出すことで、文書全体の概要を素早く理解しようという試みです。
一方、単語の登場数に応じて文字のサイズを大小させて視覚化することにより、何について書かれているのか、どんなテーマなのかが一目で分かるようにする手法として「ワードクラウド」があります。
Pythonでは簡単にワードクラウドが作成できますので、その方法について紹介致します。
今回もクラス化していますので、コピペしてすぐにお使いいただけるようにしています。
ワードクラウドの概要
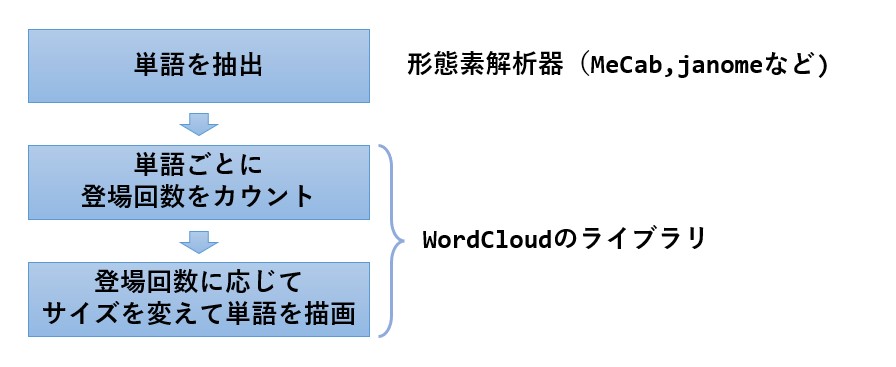
ワードクラウドは、文書から単語(動詞、名詞)を抜き出し、その登場回数に応じて文字を大きく描画することで、文書の内容やテーマを把握しやすくする手法で、下記の様な画像が作成されます。

ワードクラウドを作成する手順は以下の様になります。
- 形態素解析器を使って文書に含まれる単語を全て抽出する
- WordCloudのライブラリに抽出結果を投入する。
インストール方法
インストール手順は次の様になります。

日本語対応について
wordcloud のライブラリは日本語に対応していないので、日本語フォント(TTFファイル、又はTTCファイル)を指定する必要があります。
Windows環境であれば標準の日本語フォントを指定するだけでOKですが、英語版Linuxを使っていたり、日本語フォントの場所が分からない場合は、無料で使えるIPA Fontがあるので、これをインストールして下さい。

Windowsの場合は C:\Windows\Fonts にインストール済みのフォントが格納されています。
使いたいフォント名を右クリックし、プロパティを表示するとフォントの場所とフォントのファイル名が表示されるので、wordcloudのインスタンス生成時にこのパスとファイル名を記述します。
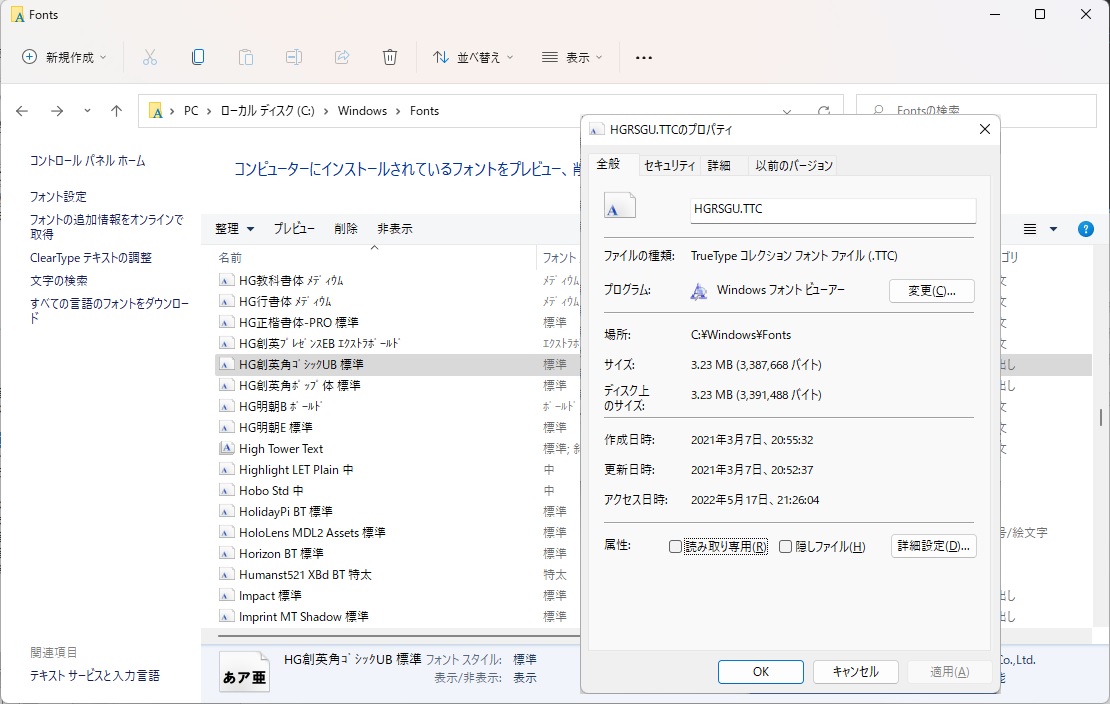
ちなみに、ここに表示されていても、実際は別の場所にインストールされている場合がありますが、これもプロパティで確認できます。
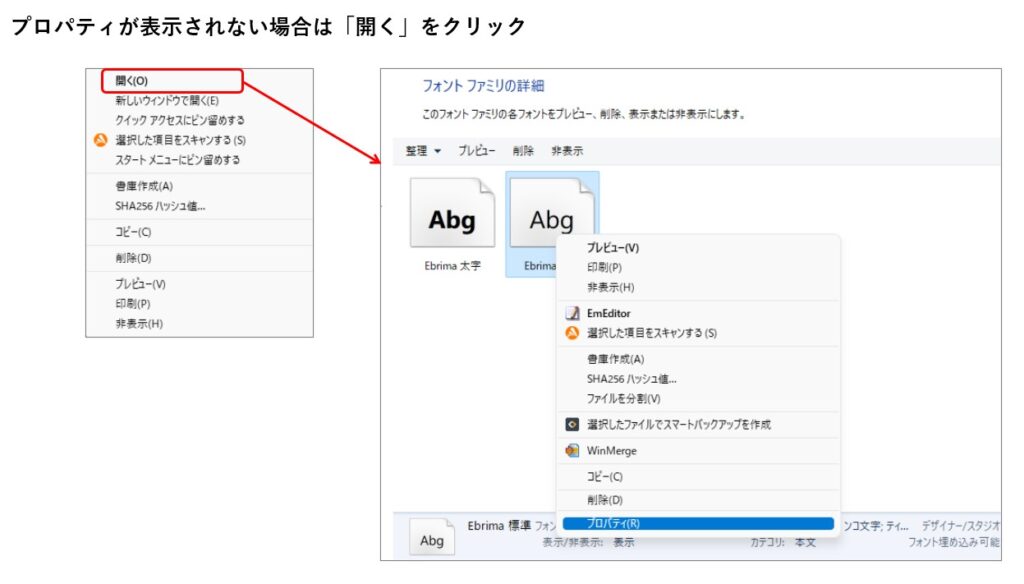
逆に、右クリックしてもプロパティが表示されないフォントが存在しますが、これはサブフォルダに格納されているからです。
「開く」をクリックするとサブフォルダが開くので、ファイル名を右クリックするとプロパティが表示されます。
ライブラリのインストール
形態素解析器は何でも良いのですが、ここでは janome を利用します。
janomeについての詳細はこちらをご覧ください。
あらかじめ、pip で janome と wordcloud のライブラリをインストールします。
#Python公式サイトからPythonをインストールした方 pip install wordcloud pip install wordcloud #anaconda経由でPythonをインストールした方 conda install -c conda-forge janome conda install -c conda-forge wordcloud
wordcloudの使い方
wordcloud を import した後、次の手順でワードクラウドを作成することが出来ます。

# ライブラリのインポート
from wordcloud import WordCloud
# テキストのサンプル
text = 'キャノン RX100 富士通 富士通 リコー RX100 RX100 RX100 キャノン ソニー ニコン ソニー パナソニック RX100 RX100 ソニー'
# Windowsにインストールされているフォントを指定
wordcloud = WordCloud(font_path='C:/Windows/Fonts/HGRSGU.TTC')
# ワードクラウドの作成
wordcloud.generate(text)
# WindowsパソコンのPドライブ直下に画像を保存
wordcloud.to_file('p:/wc.jpg')
上記のプログラムを実行すると、下記の画像が生成されます。
単語数が少ないということもありますが、デフォルトだちょっと寂しめの画像になりました。

ワードクラウド作成クラスについて
では、さっそく文書要約クラスの概要、リファレンス、ソースコードの順に紹介していきたいと思います。
クラスの概要
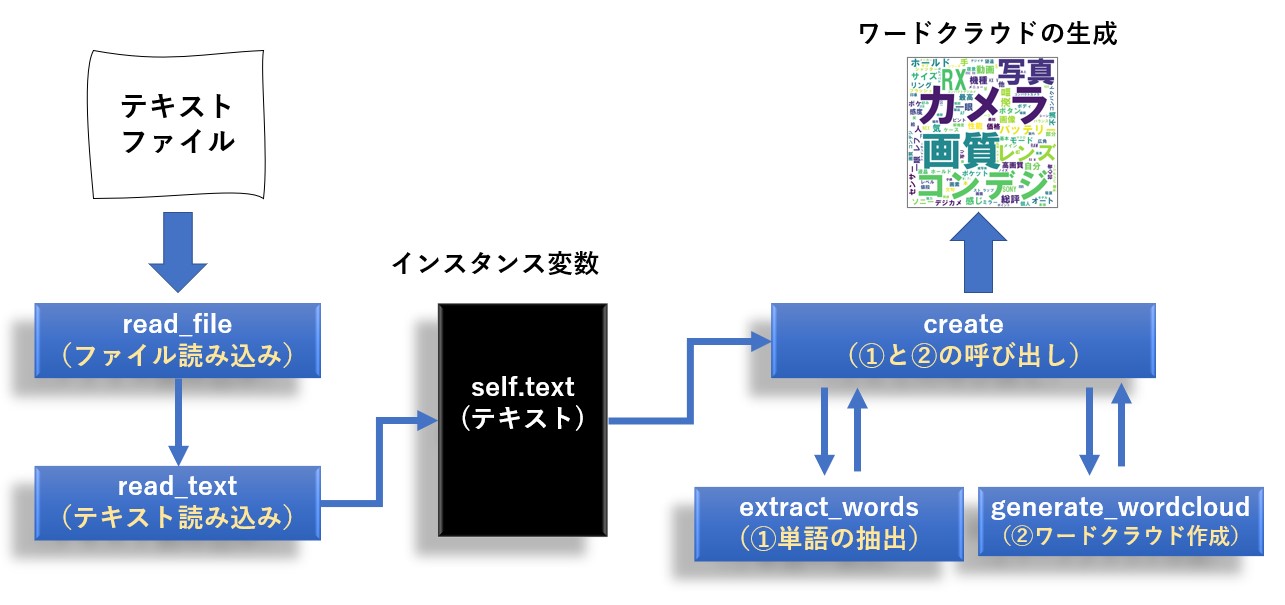
read_file 又は read_text メソッドでワードクラウド化したい文書を読み込み、create メソッドでワードクラウド画像を生成します。
リファレンス
クラス名は WordClowdMaker で、メソッドは次の6つがあります。
| 機能 | メソッド仕様 | 戻り値 | 補足 |
|---|---|---|---|
| コンストラクタ | __init__( text=None, #入力文書 font_path=None, #フォントパス width=800, #画像横サイズ height=600, #画像縦サイズ min_font_size=15 #最小サイズ ) |
ー | |
| ファイル読み込み | read_file( filename, #入力ファイル名 encoding=’utf-8′ #エンコード名 ) |
なし | |
| テキスト読み込み | read_text( text #入力文書 ) |
なし | |
| ワードクラウド の実行 |
create( path, #出力画像のパス exclusion =[] #除外単語リスト ) |
なし | exclusion =[’初代’,’基本’・・・] |
| ワードクラウド 画像の生成 |
generate_wordcloud( path, #出力画像のパス words #分かち書きテキスト ) |
なし | |
| 単語の抽出 | extract_words( text, exclusion=[] #除外単語リスト ) |
分かち書きテキスト | exclusion =[’初代’,’基本’・・・] |
プロパティは次の6つがあります。
| 意味 | メソッド仕様 | 値の例 | 補足 |
|---|---|---|---|
| フォントのフルパス | font_path | ‘C:/Windows/Font/xxxx.ttf’ | |
| ワードクラウドしたい文書 | text | ‘今日の夕食は牛丼’ | |
| 画像の背景色 | background_color | ‘white’ | |
| 画像の横サイズ | width | 800 | |
| 画像の縦サイズ | height | 600 | |
| 最小フォントサイズ | min_font_size | 15 |
使い方
クラスの使い方は次の通りです。

下記は、Pドライブに置いた startreck.txt ファイルに対してワードクラウドを作成するサンプルコードです。
wc = WordCloudMaker(font_path='C:/Windows/Fonts/HGRSGU.TTC')
wc.read_file('p:/startreck.txt')
wc.create('p:/wordcloud.png',['根幹','初代'])
画像の出力先はPドライブ直下になっていますが、必要に宇治手皆さんの環境に合わせて変更をお願いします。
下記は startreck.txt の中身です。
スタートレックは、22世紀から24世紀の話である。設定では、2026年から2053年にかけて発生した第三次世界大戦により、6億人の犠牲者と文明の崩壊が起きている。2063年にゼフラム・コクレーンがワープエンジンを開発、試験飛行中にバルカン時に発見され、ファーストコンタクトを果たした。 2151年には初代エンタープライズ号「NX-01」が竣工し、クリンゴンとのファーストコンタクトを果たしている。2153年にロミュラン人との戦争が勃発、2161年に地球連合、バルカン、アンドリアが中心になり惑星連邦が設立された。 地球人は銀河系内の約4分の1の領域に進出し、様々な異星人との交流を行っている。 既に貧困や戦争などは根絶されており、見た目や無知から来る偏見、差別も存在しない、理想的な世界となっている。 レプリケーターの登場により貨幣経済は無くなり、人間は富や欲望ではなく人間性の向上を目指して働いている。 しかし、個人財産は存在しており、ワイナリーや宇宙船を所有する一部の恵まれた人々が存在する。 惑星連邦の本部はパリにあり、宇宙艦隊の本部はサンフランシスコに存在する。 惑星連邦内では軍事力による紛争が根絶されたが、クリンゴン帝国やロミュラン帝国、カーデシア連合などの侵略的な星間国家とは必ずしも良好な関係を築けていない。 『スタートレック:エンタープライズ』では惑星連邦設立以前の時代を、『スタートレック:ディスカバリー』では、地球連合やバルカン星などが脱退、惑星連邦が瓦解した32世紀の世界が描かれている。 長く続く作品では、これまでの作品を「なかったこと」にし、設定を一新することがしばしばあるが、スタートレックのシリーズではほぼすべての作品が同じ宇宙を共有している。 一方、作品の根幹としてマルチバースの概念が取り入れられ、物語の主軸として描かれている宇宙とは異なる平行宇宙(パラレルワールド)が登場することもある。 劇場版第11作から劇場版第13作まではリブート作品ではあるが、タイムトラベルの影響で歴史が変わったという設定で、シリーズとしての連続性は保たれている。 タイムトラベルを扱った作品はスタートレックの中でしばしば登場し、異なる歴史を持つパラレルワールドがいくつも存在している。
出力した結果は以下の様になりました。
スタートレックというキーワードが「スター」と「レック」の2単語で認識されてしまったようです。
この辺は、辞書を登録するか、辞書に NEologd を使うことで解決できるでしょう。

ソースコード
クラスのソースコードは次の通りです。
import codecs
from wordcloud import WordCloud
from janome.tokenizer import Tokenizer
import re
class WordCloudMaker:
def __init__(self,text=None,font_path=None,width=800,height=600,min_font_size=15):
"""
コンストラクタ
"""
self.font_path = font_path # フォントのパス
self.text = text # クラウド化したいテキスト
self.background_color = 'white' # 画像の背景色
self.width = width # 画像の横ピクセル数
self.height = height # 画像の縦ピクセル数
self.min_font_size = min_font_size # 最小のフォントサイズ
def create(self,path,exclusion=[]):
"""
ワードクラウドの画像生成
Parameters:
path : str 画像の出力パス
exclusion : [str] 除外ワードのリスト
"""
# 名詞の抽出
words = self.extract_words(self.text,exclusion)
# ワードクラウドの画像生成
words = self.generate_wordcloud(path,words)
def generate_wordcloud(self,path,words):
"""
ワードクラウドの画像生成
Parameters:
path : str 画像の出力パス
words : [str] ワードクラウド化したい名詞リスト
"""
#ワードクラウドの画像生成
wordcloud = WordCloud(
background_color=self.background_color, # 背景色
font_path=self.font_path, # フォントのパス
width=self.width, # 画像の横ピクセル数
height=self.width, # 画像の縦ピクセル数
min_font_size=self.min_font_size # 最小のフォントサイズ
)
# ワードクラウドの作成
wordcloud.generate(words)
# 画像保存
wordcloud.to_file(path)
def extract_words(self,text,exclusion=[]):
"""
形態素解析により一般名詞と固有名詞のリストを作成
---------------
Parameters:
text : str テキスト
exclusion : [str] 除外したいワードのリスト
"""
token = Tokenizer().tokenize(text)
words = []
for line in token:
tkn = re.split('\t|,', str(line))
# 名詞のみ対象
if tkn[0] not in exclusion and tkn[1] in ['名詞'] and tkn[2] in ['一般', '固有名詞'] :
words.append(tkn[0])
return ' ' . join(words)
def read_file(self,filename):
'''
ファイルの読み込み
Parameters:
--------
filename : str 要約したい文書が書かれたファイル名
'''
with codecs.open(filename,'r','utf-8','ignore') as f:
self.read_text(f.read())
def read_text(self,text):
'''
テキストの読み込み
'''
self.text = text
まとめ
今回はワードクラウドのライブラリ wordclowd のインストール方法、使い方、そしてこれを使った自作クラスの説明、ソースコードについて紹介しました。
このクラスを使うと、簡単にワードクラウドが作成できますので、とりあえずワードクラウドがしたいという型は、コピペしてお使いください。
実際にワードクラウドを書くと、不要な単語が目に付くと思いますが、その時は 除外単語リストに記述してもらえれば除外可能です。
今は名詞だけですが、extract_words メソッドの中で動詞を含めることも可能です。
フォントを変更してみたり、色々とお試しください。
この記事が皆様のお役に立てれば幸いです。