
この操作は、データフレームで実行する必要があります。 7行5列のデータフレームを作成しましょう。
市場=データ。フレーム((market_id=c((1、2、1、4、3、4、5)。、market_name=c((「M1」、「M2」、「M3」、
「M4」、「M3」、「M4」、「M3」)。、市場=c((‘インド’、‘アメリカ合衆国’、‘インド’、‘オーストラリア’、‘アメリカ合衆国’、
‘インド’、‘オーストラリア’)。、market_type=c((‘買い物’、‘バー’、‘買い物’、「レストラン」、
‘買い物’、‘バー’、‘買い物’)。、market_squarefeet=c((120、342、220、110、342、220、110)。)。
#市場データフレームを表示する
印刷((市場)。
結果
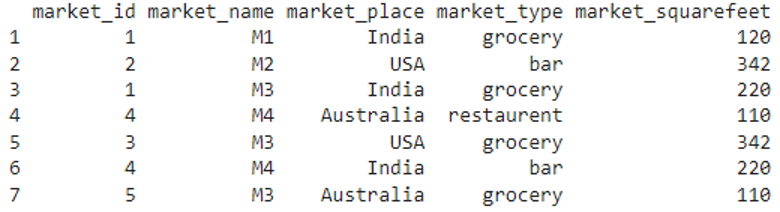
ここで、類似した値を別の列にグループ化することにより、列の平均値を返します。
方法1:Aggregate()
ここでは、3つのパラメーターを受け取るaggregate()関数を使用します。
構文
集計((dataframe_object $ grouped、 リスト((dataframe_object $ grouping)。、 楽しい=平均)。
パラメーター
- 最初のパラメーターは、グループごとの平均値を返す変数列(グループ化)を取ります。
- 2番目のパラメーターは、値がこれらの列にグループ化されるように、リスト内の単一または複数の列(グループ化)を取ります。
- 3番目のパラメーターはFUNを取ります。これは、グループ化された値の平均を返す平均関数を取ります。
例1
この例では、market_place列の値をグループ化し、market_place列でグループ化されたmarket_squarefeet列の平均値を取得します。
市場=データ。フレーム((market_id=c((1、2、1、4、3、4、5)。、market_name=c((「M1」、「M2」、「M3」、
「M4」、「M3」、「M4」、「M3」)。、市場=c((‘インド’、‘アメリカ合衆国’、‘インド’、‘オーストラリア’、‘アメリカ合衆国’、
‘インド’、‘オーストラリア’)。、market_type=c((‘買い物’、‘バー’、‘買い物’、「レストラン」、
‘買い物’、‘バー’、‘買い物’)。、market_squarefeet=c((120、342、220、110、342、220、110)。)。
#market_placeをグループ化して、グループ内の平方フィートの平均を取得します
印刷((集計((マーケット$market_squarefeet、 リスト((market $ market_place)。、 楽しい=平均)。)。
結果

market_place列の同様の値(オーストラリア、インド、および米国)がグループ化され、market_squareフィート列のグループ化された値の平均が返されることがわかります。
例2
この例では、market_type列の値をグループ化し、market_type列でグループ化されたmarket_squarefeet列の平均値を取得します。
市場=データ。フレーム((market_id=c((1、2、1、4、3、4、5)。、market_name=c((「M1」、「M2」、「M3」、
「M4」、「M3」、「M4」、「M3」)。、市場=c((‘インド’、‘アメリカ合衆国’、‘インド’、‘オーストラリア’、‘アメリカ合衆国’、
‘インド’、‘オーストラリア’)。、market_type=c((‘買い物’、‘バー’、‘買い物’、「レストラン」、
‘買い物’、‘バー’、‘買い物’)。、market_squarefeet=c((120、342、220、110、342、220、110)。)。
#market_typeをグループ化して、グループ内の平方フィートの平均を取得します
印刷((集計((マーケット$market_squarefeet、 リスト((マーケット$マーケットタイプ)。、 楽しい=平均)。)。
結果
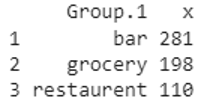
market_type列の同様の値(bar、grocery、およびrestaurent)がグループ化され、market_squareフィート列のグループ化された値の平均が返されることがわかります。
例3
この例では、market_type列とmarket_place列の値をグループ化し、market_type列とmarket_place列でグループ化されたmarket_squarefeet列の平均値を取得します。
市場=データ。フレーム((market_id=c((1、2、1、4、3、4、5)。、market_name=c((「M1」、「M2」、「M3」、
「M4」、「M3」、「M4」、「M3」)。、市場=c((‘インド’、‘アメリカ合衆国’、‘インド’、‘オーストラリア’、‘アメリカ合衆国’、
‘インド’、‘オーストラリア’)。、market_type=c((‘買い物’、‘バー’、‘買い物’、「レストラン」、
‘買い物’、‘バー’、‘買い物’)。、market_squarefeet=c((120、342、220、110、342、220、110)。)。
#market_placeとmarket_typeをグループ化して、グループ内の平方フィートの平均を取得します
印刷((集計((マーケット$market_squarefeet、 リスト((market $ market_place、マーケット$マーケットタイプ)。、 楽しい=平均)。)。
結果

2つの列の同様の値がグループ化され、market_squareフィート列のグループ化された値の平均が返されたことがわかります。
方法2:Dplyr
ここでは、dplyrライブラリで使用可能なgroup_byとsummarise_at()を使用して、mean操作でgroup_byを実行します。
構文
dataframe_object%>>%group_by((グループ化)。 %>>%summarise_at((vars((グループ化)。、 リスト((名前 = 平均)。)。
どこ:
group_by()は1つのパラメーター、つまりグループ化列を取ります
summarise_at()は2つのパラメーターを取ります:
- 最初のパラメーターは、グループごとの平均値を返す変数列(グループ化)を取ります。
- 2番目のパラメーターは、リスト全体の平均関数を取ります。
最後に、最初に平均で要約し、グループにロードします。 次に、グループ化された列をデータフレームオブジェクトにロードします。
ティブルを返します。
例1
この例では、market_place列の値をグループ化し、market_place列でグループ化されたmarket_squarefeet列の平均値を取得します。
#market_placeをグループ化して、グループ内の平方フィートの平均を取得します
印刷((市場%>>%group_by((市場)。 %>>%
summarise_at((vars((market_squarefeet)。、 リスト((名前 = 平均)。)。)。
結果

market_place列の同様の値(オーストラリア、インド、および米国)がグループ化され、market_squareフィート列のグループ化された値の平均が返されることがわかります。
例2
この例では、market_type列の値をグループ化し、market_type列でグループ化されたmarket_squarefeet列の平均値を取得します。
#market_typeをグループ化して、グループ内の平方フィートの平均を取得します
印刷((市場%>>%group_by((market_type)。 %>>%
summarise_at((vars((market_squarefeet)。、 リスト((名前 = 平均)。)。)。
結果

market_type列の同様の値(bar、grocery、およびrestaurent)がグループ化され、market_squareフィート列のグループ化された値の平均が返されることがわかります。
結論
単一または複数の列を他の数値列とグループ化して、aggregate()関数を使用して数値列の平均を返すことができます。 同様に、groupby()関数とsummarise_at()関数を使用して、列内の類似した値をグループ化し、別の列に関してグループ化された値の平均を返すことができます。
The post Groupby()平均を使用して集計操作を実行する方法 appeared first on Gamingsym Japan.