
「Pythonでは、PySparkはDataFrameを使用したsparkのような同様の種類の処理を提供するために使用されるSparkモジュールであり、指定されたデータを行と列の形式で保存します。
PySpark – pandasDataFrameはpandasDataFrameを表しますが、PySparkDataFrameを内部に保持します。
パンダはDataFrameデータ構造をサポートし、パンダはpysparkモジュールからインポートされます。
その前に、pysparkモジュールをインストールする必要があります。」
指示
インポートする構文:
pysparkからインポートパンダ
その後、pandasモジュールからデータフレームを作成または使用できます。
pandas DataFrameを作成するための構文:
pyspark.pandas.DataFrame()
辞書または値付きのリストのリストを渡すことができます。
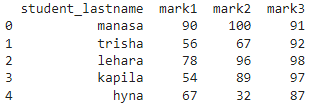
4列5行のpysparkを使用してパンダDataFrameを作成しましょう。
pysparkからインポートパンダ
#pandaspysparkからデータフレームを作成する
pyspark_pandas = pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’]、
‘mark1’:[90,56,78,54,67]、‘mark2’:[100,67,96,89,32]、‘mark3’:[91,92,98,97,87]})
print(pyspark_pandas)
出力:
次に、チュートリアルに入ります。
pysparkpandasデータフレームから一番上と最後の行を返す方法はいくつかあります。
それらを一つずつ見ていきましょう。
pyspark.pandas.DataFrame.head
head()は、pysparkpandasデータフレームの先頭から一番上の行を返します。 上から表示される行数を指定するパラメータとしてnを取ります。 デフォルトでは、上位5行が返されます。
構文:
ここで、pyspark_pandasはpysparkpandasデータフレームです。
パラメータ:
nは、pysparkpandasデータフレームの先頭からの行数を表示する整数値を指定します。
head()関数を使用して特定の列を表示することもできます。
構文:
pyspark_pandas.column.head(n)
例1
この例では、mark1列の上位2行と4行を返します。
pysparkからインポートパンダ
#pandaspysparkからデータフレームを作成する
pyspark_pandas = pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’]、‘mark1’:[90,56,78,54,67]、‘mark2’:[100,67,96,89,32]、‘mark3’:[91,92,98,97,87]})
#mark1列の上位2行を表示
print(pyspark_pandas.mark1.head(2))
print()
#mark1列の上位4行を表示
print(pyspark_pandas.mark1.head(4))
出力:
1 56
名前:mark1、dtype:int64
0 90
1 56
2 78
3 54
名前:mark1、dtype:int64
上位2行と4行がmarks1列から選択されていることがわかります。
例2
この例では、student_lastname列の上位2行と4行を返します。
pysparkからインポートパンダ
#pandaspysparkからデータフレームを作成する
pyspark_pandas = pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’]、‘mark1’:[90,56,78,54,67]、‘mark2’:[100,67,96,89,32]、‘mark3’:[91,92,98,97,87]})
#student_lastname列の上位2行を表示
print(pyspark_pandas.student_lastname.head(2))
print()
#student_lastname列の上位4行を表示
print(pyspark_pandas.student_lastname.head(4))
出力:
1 トリシャ
名前:student_lastname、dtype:オブジェクト
0 マナサ
1 トリシャ
2 レハラ
3 カピラ
名前:student_lastname、dtype:オブジェクト
上の2行と4行がから選択されたことがわかります student_lastname 桁。
例3
この例では、データフレーム全体から上位2行を返します。
pysparkからインポートパンダ
#pandaspysparkからデータフレームを作成する
pyspark_pandas = pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’]、‘mark1’:[90,56,78,54,67]、‘mark2’:[100,67,96,89,32]、‘mark3’:[91,92,98,97,87]})
#上位2行を表示
print(pyspark_pandas.head(2))
print()
#上位4行を表示
print(pyspark_pandas.head(4))
出力:
0 マナサ 90 100 91
1 トリシャ 56 67 92
student_lastname mark1 mark2 mark3
0 マナサ 90 100 91
1 トリシャ 56 67 92
2 レハラ 78 96 98
3 カピラ 54 89 97
データフレーム全体が上位2行と4行で返されることがわかります。
pyspark.pandas.DataFrame.tail
tail()は、pysparkpandasデータフレームの最後からの行を返します。 最後から表示される行数を指定するパラメーターとしてnを取ります。
構文:
ここで、pyspark_pandasはpysparkpandasデータフレームです。
パラメータ:
nは、最後のpysparkpandasデータフレームからの行数を表示する整数値を指定します。 デフォルトでは、最後の5行が返されます。
tail()関数を使用して特定の列を表示することもできます。
構文:
pyspark_pandas.column.tail(n)
例1
この例では、mark1列の最後の2行と4行を返します。
pysparkからインポートパンダ
#pandaspysparkからデータフレームを作成する
pyspark_pandas = pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’]、‘mark1’:[90,56,78,54,67]、‘mark2’:[100,67,96,89,32]、‘mark3’:[91,92,98,97,87]})
#mark1列の最後の2行を表示
print(pyspark_pandas.mark1.tail(2))
print()
#mark1列の最後の4行を表示
print(pyspark_pandas.mark1.tail(4))
出力:
4 67
名前:mark1、dtype:int64
1 56
2 78
3 54
4 67
名前:mark1、dtype:int64
最後の2行と4行がmarks1列から選択されていることがわかります。
例2
この例では、student_lastname列の最後の2行と4行を返します。
pysparkからインポートパンダ
#pandaspysparkからデータフレームを作成する
pyspark_pandas = pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’]、‘mark1’:[90,56,78,54,67]、‘mark2’:[100,67,96,89,32]、‘mark3’:[91,92,98,97,87]})
#student_lastname列の最後の2行を表示します
print(pyspark_pandas.student_lastname.tail(2))
print()
#student_lastname列の最後の4行を表示します
print(pyspark_pandas.student_lastname.tail(4))
出力:
4 ハイナ
名前:student_lastname、dtype:オブジェクト
1 トリシャ
2 レハラ
3 カピラ
4 ハイナ
名前:student_lastname、dtype:オブジェクト
最後の2行と4行がから選択されたことがわかります student_lastname 桁。
例3
この例では、データフレーム全体から最後の2行を返します。
pysparkからインポートパンダ
#pandaspysparkからデータフレームを作成する
pyspark_pandas = pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’]、‘mark1’:[90,56,78,54,67]、‘mark2’:[100,67,96,89,32]、‘mark3’:[91,92,98,97,87]})
#最後の2行を表示
print(pyspark_pandas.tail(2))
print()
#最後の4行を表示
print(pyspark_pandas.tail(4))
出力:
3 カピラ 54 89 97
4 ハイナ 67 32 87
student_lastname mark1 mark2 mark3
1 トリシャ 56 67 92
2 レハラ 78 96 98
3 カピラ 54 89 97
4 ハイナ 67 32 87
データフレーム全体が最後の2行と4行で返されることがわかります。
結論
head()関数とtail()関数を使用して、pysparkpandasデータフレームの一番上と最後の行を表示する方法を見ました。 デフォルトでは、5行を返します。head()関数とtail()関数は、特定の列を持つ最初と最後の行を取得するためにも使用されます。
The post PySparkPandasDataFrameから先頭と最後の行を返す appeared first on Gamingsym Japan.